背景
在推荐、搜索、广告等领域,CTR(click-through rate)预估是一项非常核心的技术,这里引用阿里妈妈资深算法专家朱小强大佬的一句话:“它(CTR 预估)是镶嵌在互联网技术上的明珠”。
本篇文章主要是对 CTR 预估中的常见模型进行梳理与总结,并分成模块进行概述。每个模型都会从「模型结构」、「优势」、「不足」三个方面进行探讨,在最后对所有模型之间的关系进行比较与总结。本篇文章讨论的模型如下图所示(原创图),这个图中展示了本篇文章所要讲述的算法以及之间的关系,在文章的最后总结会对这张图进行详细地说明。


目录
本篇文章将会按照整个 CTR 预估模型的演进过程进行组织,共分为 7 个大部分:
- 分布式线性模型
- Logistic Regression
- 自动化特征工程
- GBDT+LR
- FM 模型以及变体
- FM(Factorization Machines)
- FFM(Field-aware Factorization Machines)
- AFM(Attentional Factorization Machines)
- Embedding+MLP 结构下的浅层改造
- FNN(Factorization Machine supported Neural Network)
- PNN(Product-based Neural Network)
- NFM(Neural Factorization Machines)
- ONN(Operation-aware Neural Networks)
- 双路并行的模型组合
- wide&deep(Wide and Deep)
- deepFM(Deep Factorization Machines)
- 复杂的显式特征交叉网络
- DCN(Deep and Cross Network)
- xDeepFM(Compressed Interaction Network)
- AutoInt(Automatic Feature Interaction Learning)
- CTR 预估模型总结与比较
- CTR 预估模型关系图谱
- CTR 预估模型特性对比
一。 分布式线性模型
Logistic Regression
Logistic Regression 是每一位算法工程师再也熟悉不过的基本算法之一了,毫不夸张地说,LR 作为最经典的统计学习算法几乎统治了早期工业机器学习时代。这是因为其具备简单、时间复杂度低、可大规模并行化等优良特性。在早期的 CTR 预估中,算法工程师们通过手动设计交叉特征以及特征离散化等方式,赋予 LR 这样的线性模型对数据集的非线性学习能力,高维离散特征 + 手动交叉特征构成了 CTR 预估的基础特征。LR 在工程上易于大规模并行化训练恰恰适应了这个时代的要求。
模型结构:
优势:
- 模型简单,具备一定可解释性
- 计算时间复杂度低
- 工程上可大规模并行化
不足:
- 依赖于人工大量的特征工程,例如需要根据业务背知识通过特征工程融入模型
- 特征交叉难以穷尽
- 对于训练集中没有出现的交叉特征无法进行参数学习
二。 自动化特征工程
GBDT + LR(2014)—— 特征自动化时代的初探索
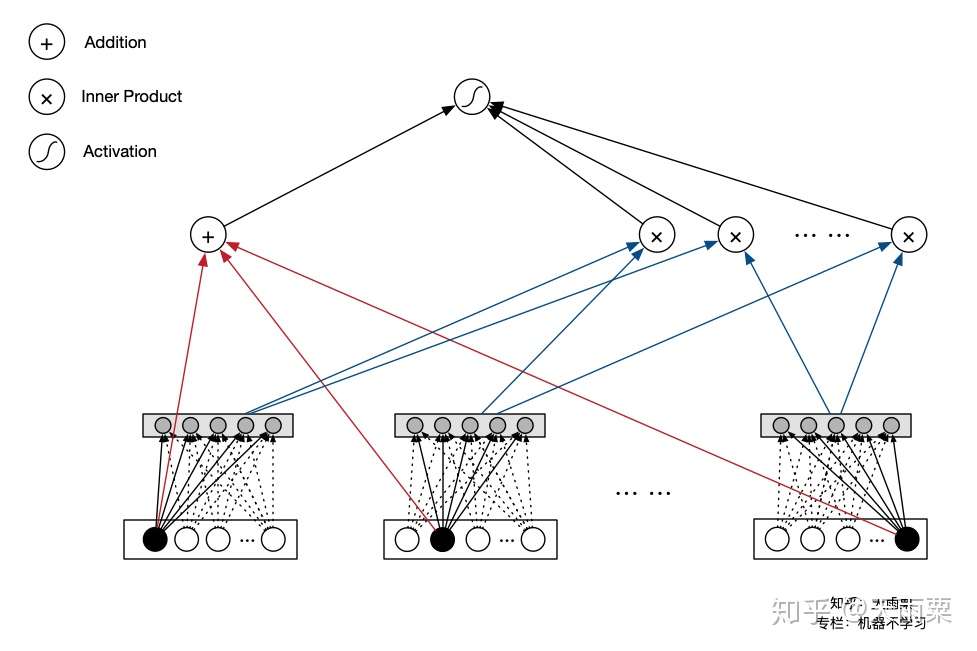
Facebook 在 2014 年提出了 GBDT+LR 的组合模型来进行 CTR 预估,其本质上是通过 Boosting Tree 模型本身的特征组合能力来替代原先算法工程师们手动组合特征的过程。GBDT 等这类 Boosting Tree 模型本身具备了特征筛选能力(每次分裂选取增益最大的分裂特征与分裂点)以及高阶特征组合能力(树模型天然优势),因此通过 GBDT 来自动生成特征向量就成了一个非常自然的思路。注意这里虽然是两个模型的组合,但实际并非是端到端的模型,而是两阶段的、解耦的,即先通过 GBDT 训练得到特征向量后,再作为下游 LR 的输入,LR 的在训练过程中并不会对 GBDT 进行更新。
模型结构:
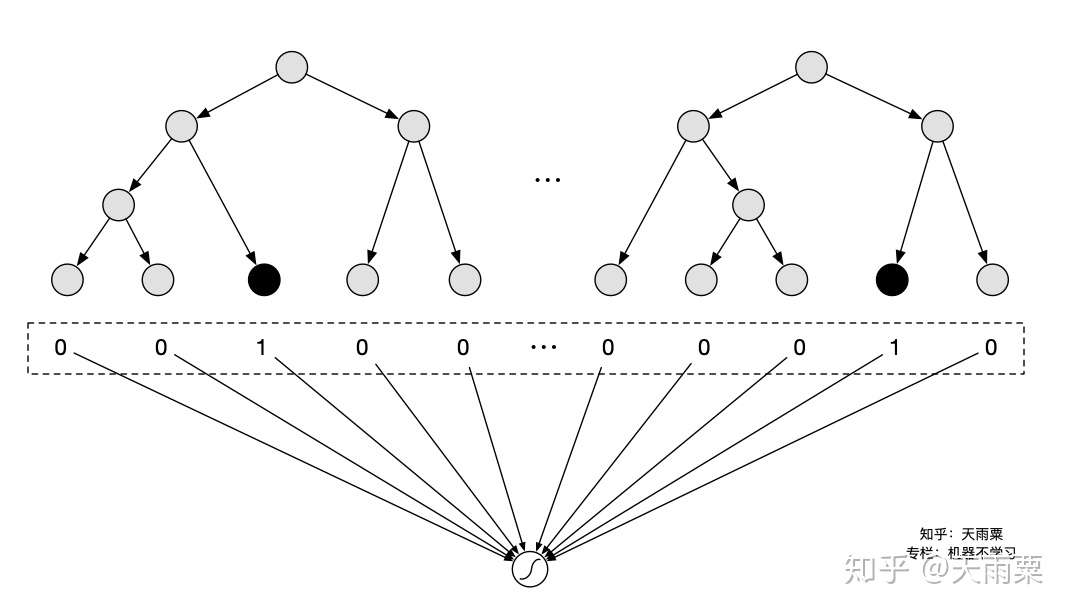
通过 GBDT 训练模型,得到组合的特征向量。例如训练了两棵树,每棵树有 5 个叶子结点,对于某个特定样本来说,落在了第一棵树的第 3 个结点,此时我们可以得到向量 ;落在第二棵树的第 4 个结点,此时的到向量
;那么最终通过 concat 所有树的向量,得到这个样本的最终向量
。将这个向量作为下游 LR 模型的 inputs,进行训练。
优势:
- 特征工程自动化,通过 Boosting Tree 模型的天然优势自动探索特征组合
不足:
- 两阶段的、非端到端的模型
- CTR 预估场景涉及到大量高维稀疏特征,树模型并不适合处理(因此实际上会将 dense 特征或者低维的离散特征给 GBDT,剩余高维稀疏特征在 LR 阶段进行训练)
- GBDT 模型本身比较复杂,无法做到 online learning,模型对数据的感知相对较滞后(必须提高离线模型的更新频率)
三。 FM 模型以及变体
(1)FM:Factorization Machines, 2010 —— 隐向量学习提升模型表达
FM 是在 2010 年提出的一种可以学习二阶特征交叉的模型,通过在原先线性模型的基础上,枚举了所有特征的二阶交叉信息后融入模型,提高了模型的表达能力。但不同的是,模型在二阶交叉信息的权重学习上,采用了隐向量内积(也可看做 embedding)的方式进行学习。
模型结构:
FM 的公式包含了一阶线性部分与二阶特征交叉部分:
在 LR 中,一般是通过手动构造交叉特征后,喂给模型进行训练,例如我们构造性别与广告类别的交叉特征: (gender='女' & ad_category='美妆'),此时我们会针对这个交叉特征学习一个参数
。但是在 LR 中,参数梯度更新公式与该特征取值
关系密切:
,当
取值为 0 时,参数
就无法得到更新,而
要非零就要求交叉特征的两项都要非零,但实际在数据高度稀疏,一旦两个特征只要有一个取 0,参数
不能得到有效更新;除此之外,对于训练集中没有出现的交叉特征,也没办法学习这类权重,泛化性能不够好。
另外,在 FM 中通过将特征隐射到 k 维空间求内积的方式,打破了交叉特征权重间的隔离性(break the independence of the interaction parameters),增加模型在稀疏场景下学习交叉特征的能力。一个交叉特征参数的估计,可以帮助估计其他相关的交叉特征参数。例如,假设我们有交叉特征 gender=male & movie_genre=war,我们需要估计这个交叉特征前的参数 ,FM 通过将
分解为
的方式进行估计,那么对于每次更新 male 或者 war 的隐向量
时,都会影响其他与 male 或者 war 交叉的特征参数估计,使得特征权重的学习不再互相独立。这样做的好处是,对于 traindata set 中没有出现过的交叉特征,FM 仍然可以给到一个较好的非零预估值。
优势:
- 可以有效处理稀疏场景下的特征学习
- 具有线性时间复杂度(化简思路:
)
- 对训练集中未出现的交叉特征信息也可进行泛化
不足:
- 2-way 的 FM 仅枚举了所有特征的二阶交叉信息,没有考虑高阶特征的信息
FFM(Field-aware Factorization Machine)是 Yuchin Juan 等人在 2015 年的比赛中提出的一种对 FM 改进算法,主要是引入了 field 概念,即认为每个 feature 对于不同 field 的交叉都有不同的特征表达。FFM 相比于 FM 的计算时间复杂度更高,但同时也提高了本身模型的表达能力。FM 也可以看成只有一个 field 的 FFM,这里不做过多赘述。
(2)AFM:Attentional Factorization Machines, 2017 —— 引入 Attention 机制的 FM
AFM 全称 Attentional Factorization Machines,顾名思义就是引入 Attention 机制的 FM 模型。我们知道 FM 模型枚举了所有的二阶交叉特征(second-order interactions),即 ,实际上有一些交叉特征可能与我们的预估目标关联性不是很大;AFM 就是通过 Attention 机制来学习不同二阶交叉特征的重要性(这个思路与 FFM 中不同 field 特征交叉使用不同的 embedding 实际上是一致的,都是通过引入额外信息来表达不同特征交叉的重要性)。
举例来说,在预估用户是否会点击广告时,我们假设有用户性别、广告版位尺寸大小、广告类型三个特征,分别对应三个 embedding: ,
,
,对于用户“是否点击”这一目标
来说,显然性别与 ad_size 的交叉特征对于
的相关度不大,但性别与 ad_category 的交叉特征(如 gender= 女性&category= 美妆)就会与
更加相关;换句话说,我们认为当性别与 ad_category 交叉时,重要性应该要高于性别与 ad_size 的交叉;FFM 中通过引入 Field-aware 的概念来量化这种与不同特征交叉时的重要性,AFM 则是通过加入 Attention 机制,赋予重要交叉特征更高的重要性。
模型结构:
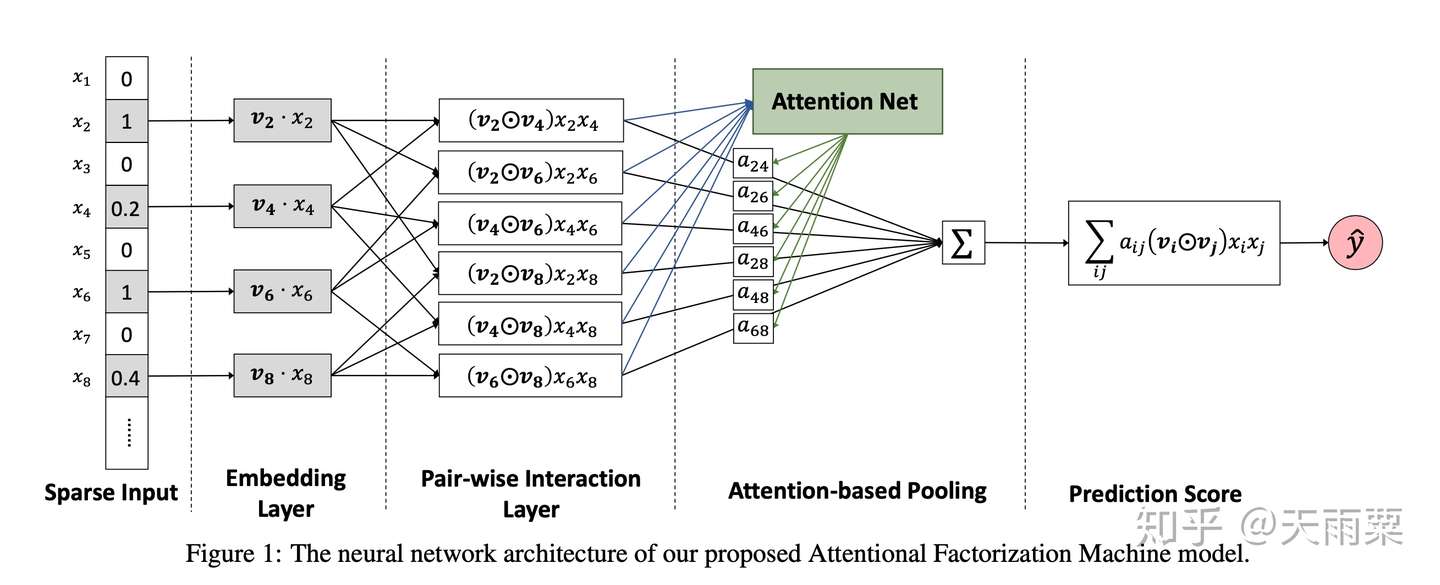
AFM 在 FM 的二阶交叉特征上引入 Attention 权重,公式如下:
其中
代表 element-wise 的向量相乘,下同。
其中, 是模型所学习到的
与
特征交叉的重要性,其公式如下:
我们可以看到这里的权重 实际是通过输入
和
训练了一个一层隐藏层的 NN 网络,让模型自行去学习这个权重。
对比 AFM 和 FM 的公式我们可以发现,AFM 实际上是 FM 的更加泛化的一种形式。当我们令向量 ,权重
时,AFM 就会退化成 FM 模型。
优势:
- 在 FM 的二阶交叉项上引入 Attention 机制,赋予不同交叉特征不同的重要度,增加了模型的表达能力
- Attention 的引入,一定程度上增加了模型的可解释性
不足:
- 仍然是一种浅层模型,模型没有学习到高阶的交叉特征
四。 Embedding+MLP 结构下的浅层改造
本章所介绍的都是具备 Embedding+MLP 这样结构的模型,之所以称作浅层改造,主要原因在于这些模型都是在 embedding 层进行的一些改变,例如 FNN 的预训练 Embedding、PNN 的 Product layer、NFM 的 Bi-Interaction Layer 等等,这些改变背后的思路可以归纳为:使用复杂的操作让模型在浅层尽可能包含更多的信息,降低后续下游 MLP 的学习负担。
(1)FNN: Factorisation Machine supported Neural Network, 2016 —— 预训练 Embedding 的 NN 模型
FNN 是 2016 年提出的一种基于 FM 预训练 Embedding 的 NN 模型,其思路也比较简单;FM 本身具备学习特征 Embedding 的能力,DNN 具备高阶特征交叉的能力,因此将两者结合是很直接的思路。FM 预训练的 Embedding 可以看做是“先验专家知识”,直接将专家知识输入 NN 来进行学习。注意,FNN 本质上也是两阶段的模型,与 Facebook 在 2014 年提出 GBDT+LR 模型在思想上一脉相承。
模型结构:
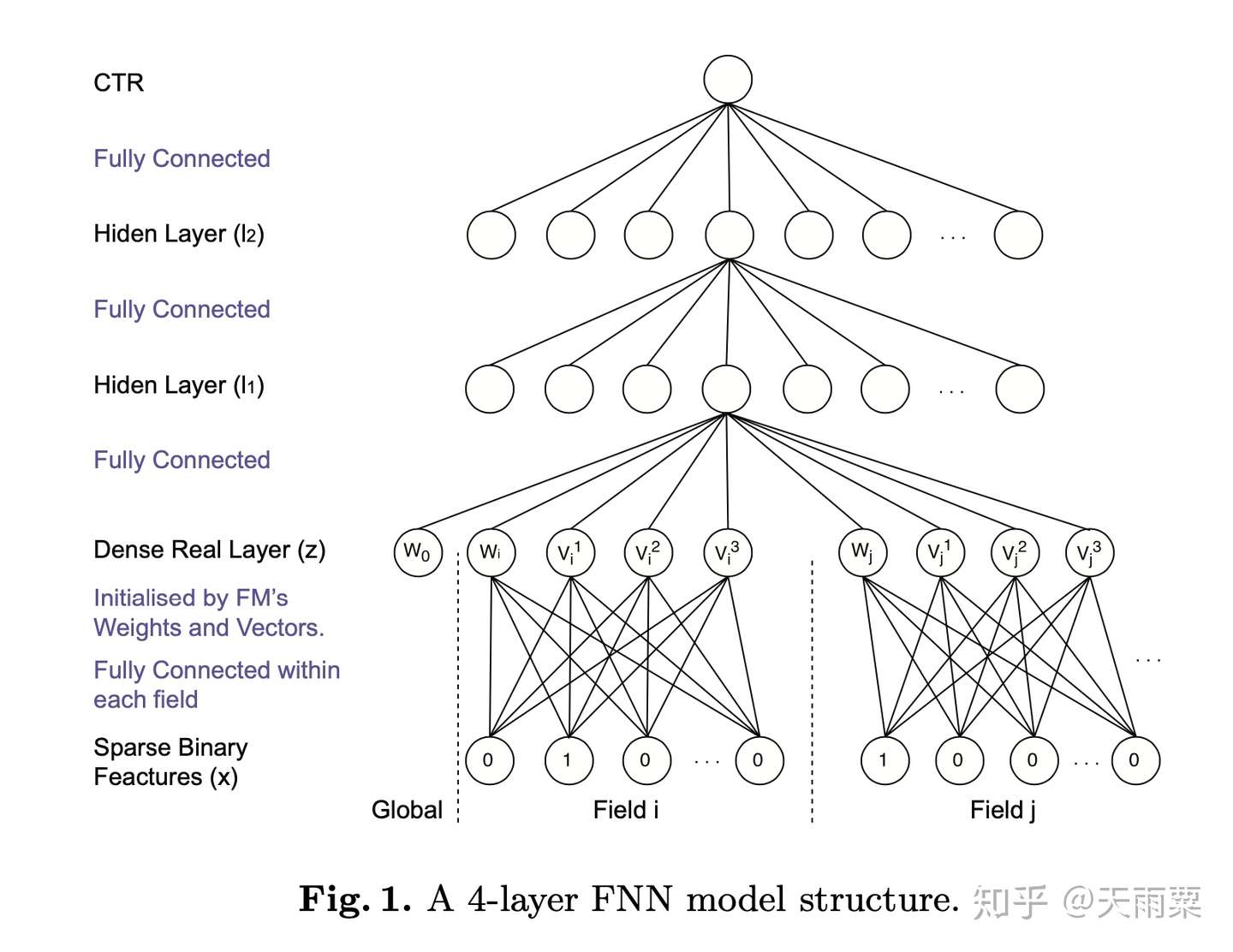
FNN 本身在结构上并不复杂,如上图所示,就是将 FM 预训练好的 Embedding 向量直接喂给下游的 DNN 模型,让 DNN 来进行更高阶交叉信息的学习。
优势:
- 离线训练 FM 得到 embedding,再输入 NN,相当于引入先验专家经验
- 加速模型的训练和收敛
- NN 模型省去了学习 feature embedding 的步骤,训练开销低
不足:
- 非端到端的两阶段模型,不利于 online learning
- 预训练的 Embedding 受到 FM 模型的限制
- FNN 中只考虑了特征的高阶交叉,并没有保留低阶特征信息
(2)PNN:Product-based Neural Network, 2016 —— 引入不同 Product 操作的 Embedding 层
PNN 是 2016 年提出的一种在 NN 中引入 Product Layer 的模型,其本质上和 FNN 类似,都属于 Embedding+MLP 结构。作者认为,在 DNN 中特征 Embedding 通过简单的 concat 或者 add 都不足以学习到特征之间复杂的依赖信息,因此 PNN 通过引入 Product Layer 来进行更复杂和充分的特征交叉关系的学习。PNN 主要包含了 IPNN 和 OPNN 两种结构,分别对应特征之间 Inner Product 的交叉计算和 Outer Product 的交叉计算方式。
模型结构:
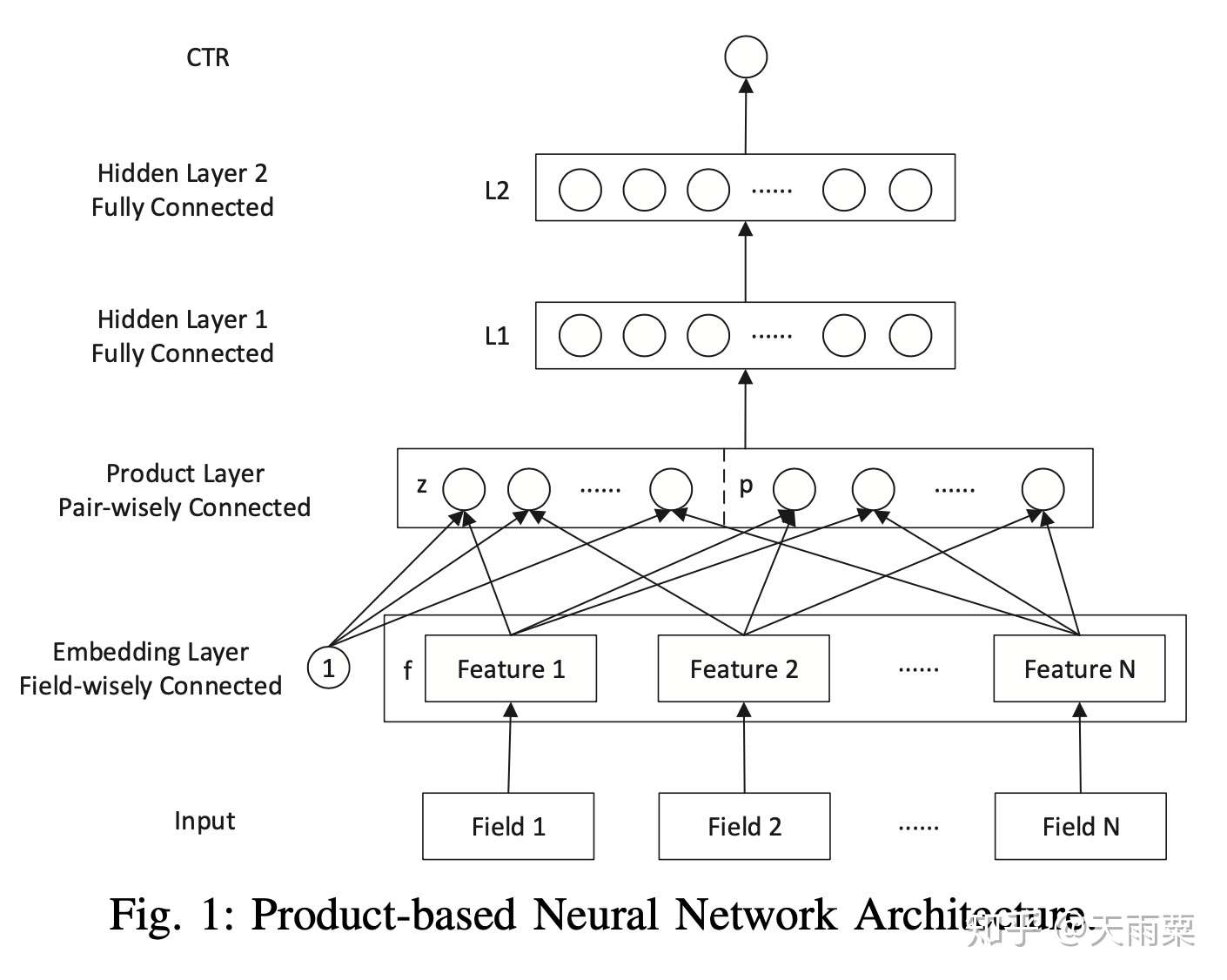
PNN 结构显示通过 Embedding Lookup 得到每个 field 的 Embedding 向量,接着将这些向量输入 Product Layer,在 Product Layer 中包含了两部分,一部分是左边的 ,就是将特征原始的 Embedding 向量直接保留;另一部分是右侧的
,即对应特征之间的 product 操作;可以看到 PNN 相比于 FNN 一个优势就是保留了原始的低阶 embedding 特征。
在 PNN 中,由于引入 Product 操作,会使模型的时间和空间复杂度都进一步增加。这里以 IPNN 为例,其中 是 pair-wise 的特征交叉向量,假设我们共有 N 个特征,每个特征的 embedding 信息
;在 Inner Product 的情况下,通过交叉项公式
会得到
(其中
是对称矩阵),此时从 Product 层到
层(假设
层有
个结点),对于
层的每个结点我们有:
,因此这里从 product layer 到 L1 层参数空间复杂度为
;作者借鉴了 FM 的思想对参数
进行了矩阵分解:
,此时 L1 层每个结点的计算可以化简为:
,空间复杂度退化
。
优势:
- PNN 通过
保留了低阶 Embedding 特征信息
- 通过 Product Layer 引入更复杂的特征交叉方式,
不足:
- 计算时间复杂度相对较高
(3)NFM:Neural Factorization Machines, 2017 —— 引入 Bi-Interaction Pooling 结构的 NN 模型
NFM 全程为 Neural Factorization Machines,它与 FNN 一样,都属于将 FM 与 NN 进行结合的模型。但不同的是 NFM 相比于 FNN 是一种端到端的模型。NFM 与 PNN 也有很多相似之出,本质上也属于 Embedding+MLP 结构,只是在浅层的特征交互上采用了不同的结构。NFM 将 PNN 的 Product Layer 替换成了 Bi-interaction Pooling 结构来进行特征交叉的学习。
模型结构:
NFM 的整个模型公式为:
其中 是 Bi-Interaction Pooling+NN 部分的输出结果。我们重点关注 NFM 中的 Bi-Interaction Pooling 层:

NFM 的结构如上图所示,通过对特征 Embedding 之后,进入 Bi-Interaction Pooling 层。这里注意一个小细节,NFM 的对 Dense Feature,Embedding 方式于 AFM 相同,将 Dense Feature Embedding 以后再用 dense feature 原始的数据进行了 scale,即 。
NFM 的 Bi-Interaction Pooling 层是对两两特征的 embedding 进行 element-wise 的乘法,公式如下:
假设我们每个特征 Embedding 向量的维度为 ,则
,Bi-Interaction Pooling 的操作简单来说就是将所有二阶交叉的结果向量进行 sum pooling 后再送入 NN 进行训练。对比 AFM 的 Attention 层,Bi-Interaction Pooling 层采用直接 sum 的方式,缺少了 Attention 机制;对比 FM 莫明星,NFM 如果将后续 DNN 隐藏层删掉,就会退化为一个 FM 模型。
NFM 在输入层以及 Bi-Interaction Pooling 层后都引入了 BN 层,也加速了模型了收敛。
优势:
- 相比于 Embedding 的 concat 操作,NFM 在 low level 进行 interaction 可以提高模型的表达能力
- 具备一定高阶特征交叉的能力
- Bi-Interaction Pooling 的交叉具备线性计算时间复杂度
不足:
- 直接进行 sum pooling 操作会损失一定的信息,可以参考 AFM 引入 Attention
(4)ONN:Operation-aware Neural Network, 2019 —— FFM 与 NN 的结合体
ONN 是 2019 年发表的 CTR 预估,我们知道 PNN 通过引入不同的 Product 操作来进行特征交叉,ONN 认为针对不同的特征交叉操作,应该用不同的 Embedding,如果用同样的 Embedding,那么各个不同操作之间就会互相影响而最终限制了模型的表达。
我们会发现 ONN 的思路在本质上其实和 FFM、AFM 都有异曲同工之妙,这三个模型都是通过引入了额外的信息来区分不同 field 之间的交叉应该具备不同的信息表达。总结下来:
- FFM:引入 Field-aware,对于 field a 来说,与 field b 交叉和 field c 交叉应该用不同的 embedding
- AFM:引入 Attention 机制,a 与 b 的交叉特征重要度与 a 与 c 的交叉重要度不同
- ONN:引入 Operation-aware,a 与 b 进行内积所用的 embedding,不同于 a 与 b 进行外积用的 embedding
对比上面三个模型,本质上都是给模型增加更多的表达能力,个人觉得 ONN 就是 FFM 与 NN 的结合。
模型结构:
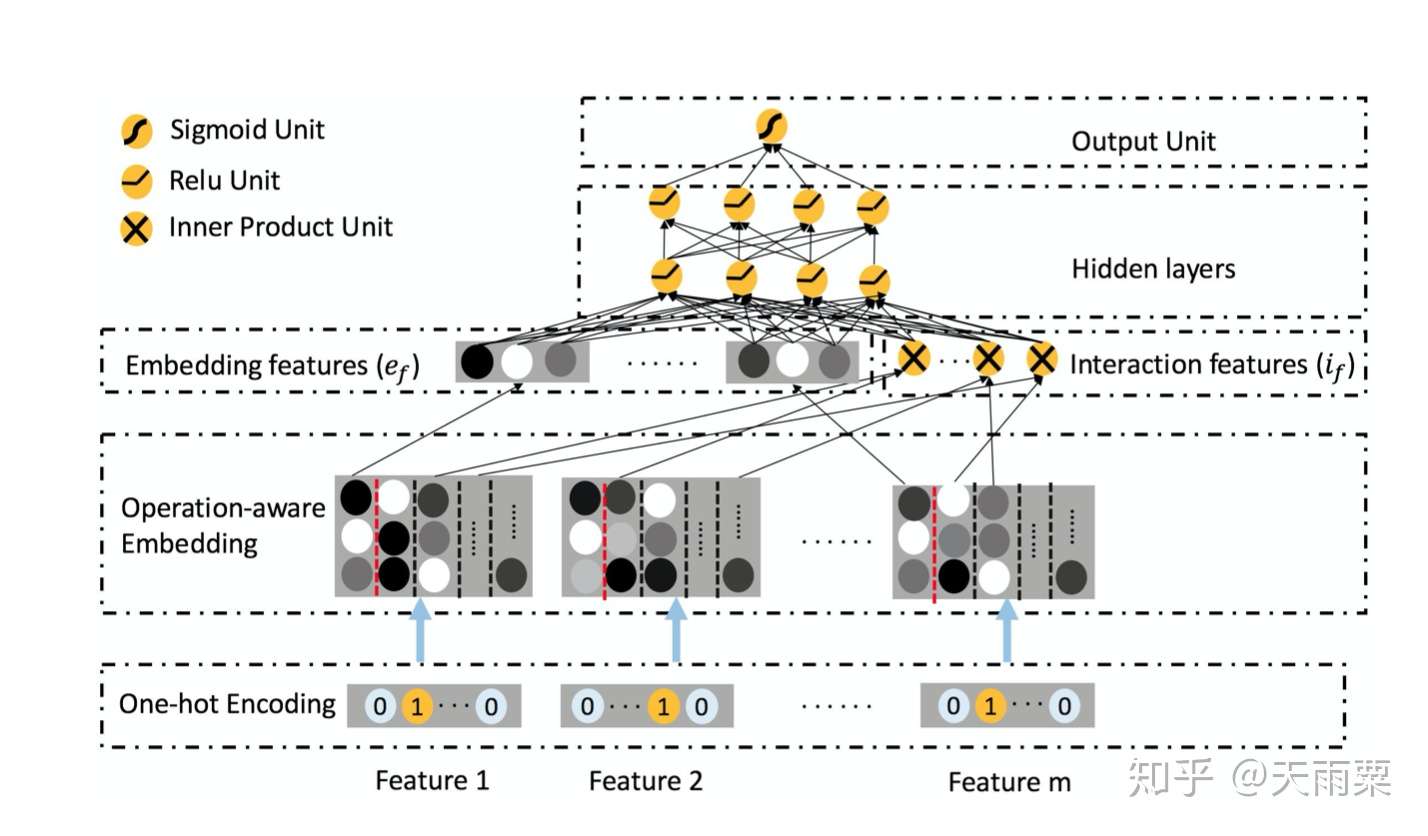
ONN 沿袭了 Embedding+MLP 结构。在 Embedding 层采用 Operation-aware Embedding,可以看到对于一个 feature,会得到多个 embedding 结果;在图中以红色虚线为分割,第一列的 embedding 是 feature 本身的 embedding 信息,从第二列开始往后是当前特征与第 n 个特征交叉所使用的 embedding。
在 Embedding features 层中,我们可以看到包含了两部分:
- 左侧部分为每个特征本身的 embedding 信息,其代表了一阶特征信息
- 右侧部分是与 FFM 相同的二阶交叉特征部分
这两部分 concat 之后接入 MLP 得到最后的预测结果。
优势:
- 引入 Operation-aware,进一步增加了模型的表达能力
- 同时包含了特征一阶信息与高阶交叉信息
不足:
- 模型复杂度相对较高,每个 feature 对应多个 embedding 结果
五。 双路并行的模型组合
这一部分将介绍双路并行的模型结构,之所以称为双路并行,是因为在这一部分的模型中,以 Wide&Deep 和 DeepFM 为代表的模型架构都是采用了双路的结构。例如 Wide&Deep 的左路为 Embedding+MLP,右路为 Cross Feature LR;DeepFM 的左路为 FM,右路为 Embedding+MLP。这类模型通过使用不同的模型进行联合训练,不同子模型之间互相弥补,增加整个模型信息表达和学习的多样性。
(1)WDL:Wide and Deep Learning, 2016 —— Memorization 与 Generalization 的信息互补
Wide And Deep 是 2016 年 Google 提出的用于 Google Play app 推荐业务的一种算法。其核心思想是通过结合 Wide 线性模型的记忆性(memorization)和 Deep 深度模型的泛化性(generalization)来对用户行为信息进行学习建模。
模型结构:
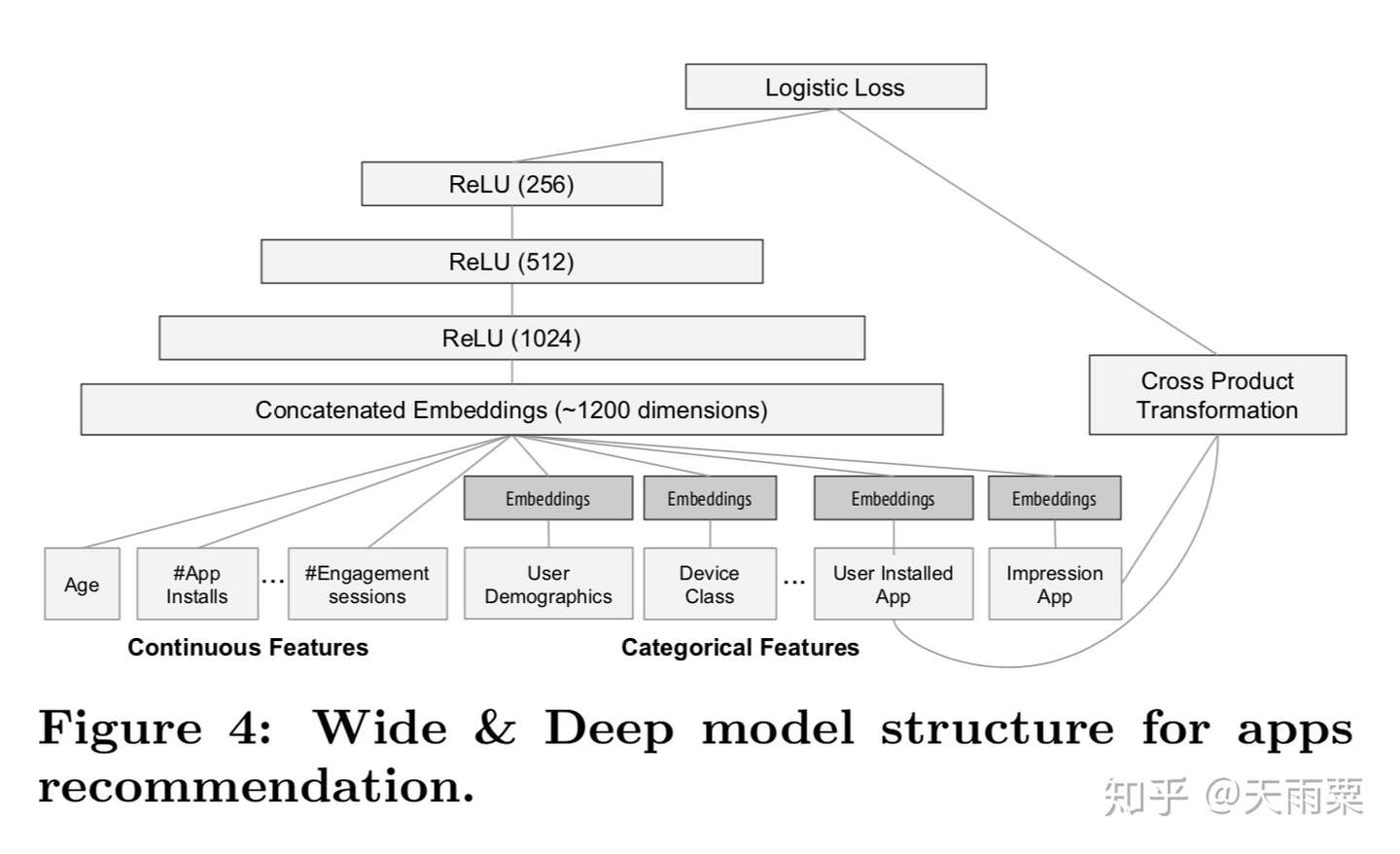
优势:
- Wide 层与 Deep 层互补互利,Deep 层弥补 Memorization 层泛化性不足的问题
- wide 和 deep 的 joint training 可以减小 wide 部分的 model size(即只需要少数的交叉特征)
- 可以同时学习低阶特征交叉(wide 部分)和高阶特征交叉(deep 部分)
不足:
- 仍需要手动设计交叉特征
(2)DeepFM:Deep Factorization Machines, 2017 —— FM 基础上引入 NN 隐式高阶交叉信息
我们知道 FM 只能够去显式地捕捉二阶交叉信息,而对于高阶的特征组合却无能为力。DeepFM 就是在 FM 模型的基础上,增加 DNN 部分,进而提高模型对于高阶组合特征的信息提取。DeepFM 能够做到端到端的、自动的进行高阶特征组合,并且不需要人工干预。
模型结构:
DeepFM 包含了 FM 和 NN 两部分,这两部分共享了 Embedding 层:
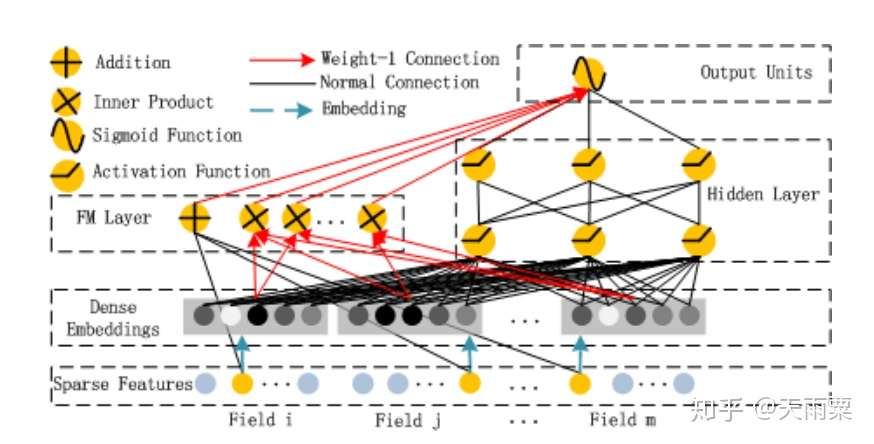
左侧 FM 部分就是 2-way 的 FM:包含了线性部分和二阶交叉部分右侧 NN 部分与 FM 共享 Embedding,将所有特征的 embedding 进行 concat 之后作为 NN 部分的输入,最终通过 NN 得到。
优势:
- 模型具备同时学习低阶与高阶特征的能力
- 共享 embedding 层,共享了特征的信息表达
不足:
- DNN 部分对于高阶特征的学习仍然是隐式的
六。 复杂的显式特征交叉网络
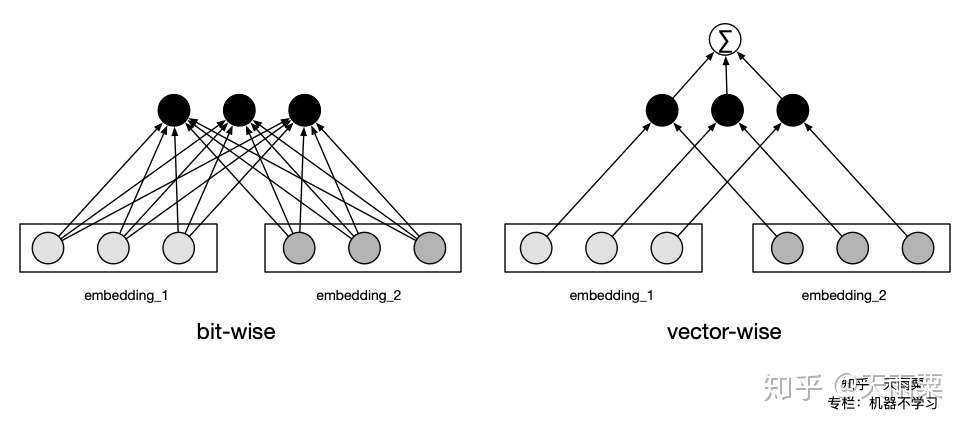
无论是以 FNN、PNN、NFM、ONN 为代表的 Embedding+MLP,还是以 Wide&Deep 和 DeepFM 为代表的双路模型,基本都是通过 DNN 来学习高阶特征交叉信息。但 DNN 本身对于特征交叉是隐式的(Implicit)、bit-wise 的,因此在这一阶段,以 DCN、xDeepFM、AutoInt 为代表的模型均把思路放在如何以 Explicit 的方式学习有限阶(bounded-degree)的特征交叉信息上。
Bit-wise:even the elements within the same field embedding vector will influence each other.
(1)Deep&Cross:Deep and Cross Network, 2017 —— 显式交叉网络 Cross Net 的诞生
Deep&Cross 其实也属于双路并行的模型结构,只不过提出了一种新的模型叫做 Cross Net 来替代 DeepFM 中的 FM 部分。DNN 本身虽然具备高阶交叉特征的学习能力,但其对于特征交叉的学习是隐式的、高度非线性的一种方式,因此作者提出了 Cross Net,它可以显式地进行特征的高阶交叉,CrossNet 相比于 DNN 的优势主要在于:
- 可以显式地(Explicitly)学习有限阶(bounded-degree)的特征交叉
- 计算时间复杂度相比于 DNN 更加低
模型结构:
DCN 模型包含了两部分,左边一路是通过 CrossNet 来显式地学习有限阶特征交叉,右边一路是通过 DNN 来隐式学习交叉特征,进一步提高模型的多样性和表达能力。
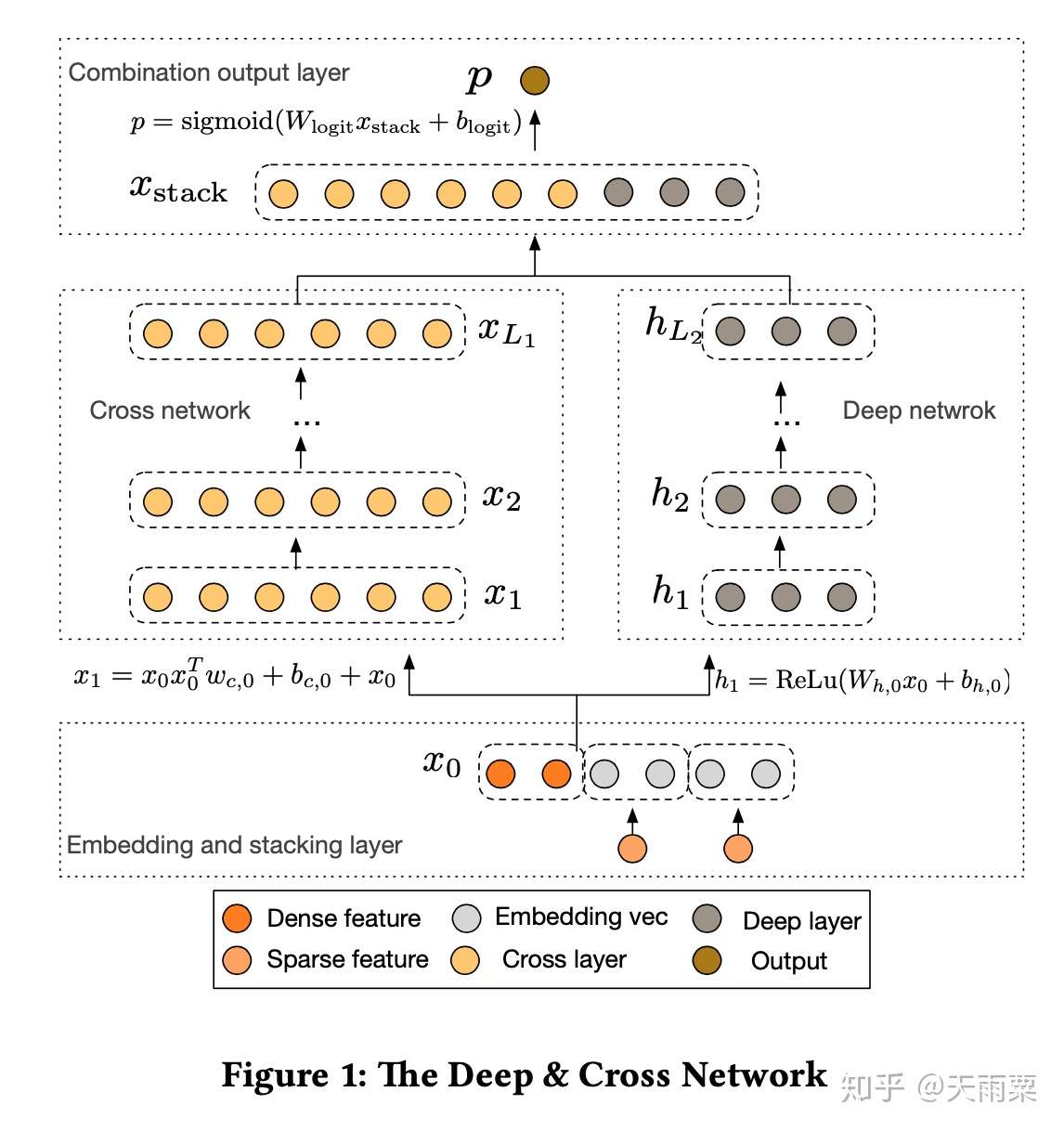
CrossNet 的主要思想是显式地计算内积来进行层与层之间的信息交叉;另外,CrossNet 在设计上还借鉴了残差网络的思想,使得每一层的输出结果能够包含原始的输入信息。
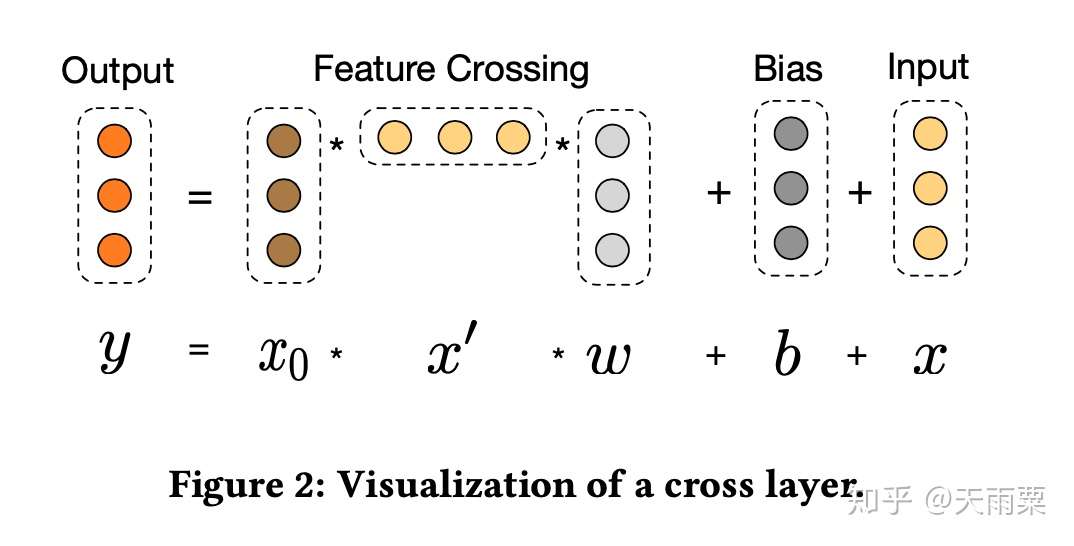
对于 CrossNet 中的某一层,其计算方法如上图所示。分为三部分:
- Feature Crossing:对 input embeddings 与上一层的输出进行交叉
- Bias:偏置项
- Input:上一层的输出(也是本层的输入)
公式可以表达为:
其中 ,通过上式得到
,我们可以发现 mapping function
正好在拟合两层网络之间的残差。对于 CrossNet 中的第
层,其能够捕捉到的特征交叉的最高阶为
。
CrossNet 本身在计算消耗上也不大,假设 CrossNet 共有 层,输入的 input vector 是一个
维向量,那么对于每一层来说有
两个参数,即
个参数,总共
层,共有
个参数,参数规模与输入的维度
呈线性相关。
优势:
- 具备显式高阶特征交叉的能力
- 结合 ResNet 的思想,可以将原始信息在 CrossNet 中进行传递
不足:
- CrossNet 在进行交叉时是 bit-wise 方式
- CrossNet 最终的输出有一定的局限性,CrossNet 的每一层输出都是输入向量
的标量倍,这种形式在一定程度上限制了模型的表达能力
证明: 我们令 CrossNet 的输入为
,忽略每一层中的 bias 项,对于第一次 cross,有:
,其中
; 对于第二次 cross,有:
,其中
基于上式进行推广可以得到
,即证得 CrossNet 的输出是输入
与
也是关于
(2)xDeepFM: eXtreme Deep Factorization Machine, 2018 —— Compressed Interaction Network 的诞生
xDeepFM 全称为 eXtreme Deep Factorization Machine,可以看出其是在 DeepFM 基础上进行了改进。xDeepFM 的贡献主要在于提出了压缩交互网络(Compressed Interaction Network),与 DCN 相同的是,都提出了要 cross feature explicitly;但不同的是,DCN 中的特征交叉是 element-wise 的,而 CIN 中的特征交叉是 vector-wise 的。
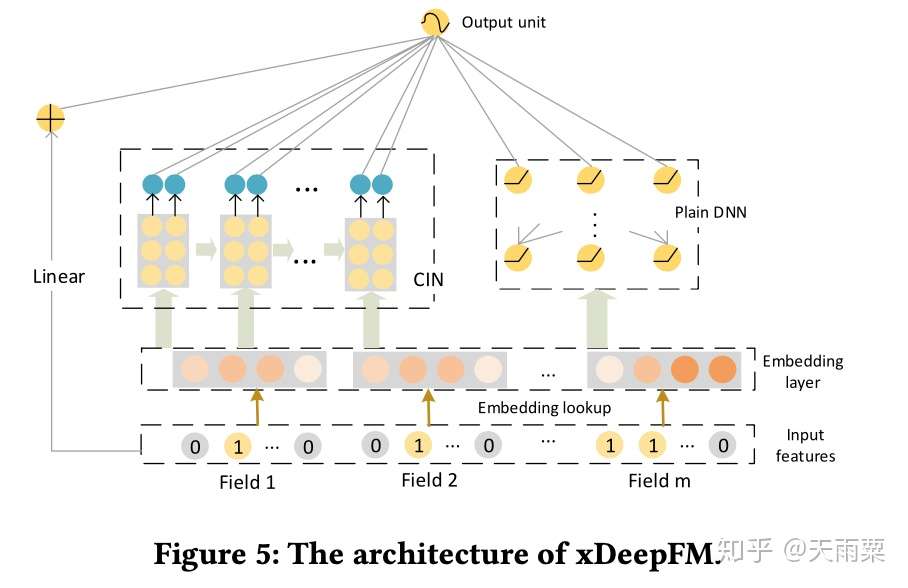
模型结构:
xDeepFM 模型结构如下,整个模型分为三个部分:
- Linear Part:捕捉线性特征
- CIN Part:压缩交互网络,显式地、vector-wise 地学习高阶交叉特征
- DNN Part:隐式地、bit-wise 地学习高阶交叉特征
CIN 网络的设计主要分为两步:交互(interaction)与压缩(compression)。
在交互部分,如下图(a)所示,将第 层的 feature map 与
(输入层,这里将输入层表示为一个
的 tensor,其中 m 为特征个数,D 为 embedding 的 size)。在 D 的每一个维度上,进行外积计算,得到
。
在压缩部分,借鉴了 CNN 卷积 +Pooling 的思想,先通过 个 filter 将三维的
(可看做一张图片)进行压缩计算,得到
。紧接着在 D 维上进行 sum pooling 操作,得到最后输出向量(如 c 图中的黄色小圆圈)。
经过多个串行的压缩与交互步骤,可以得到多个输出向量,最终将这些向量 concat 起来,作为 CIN 的输出结果。
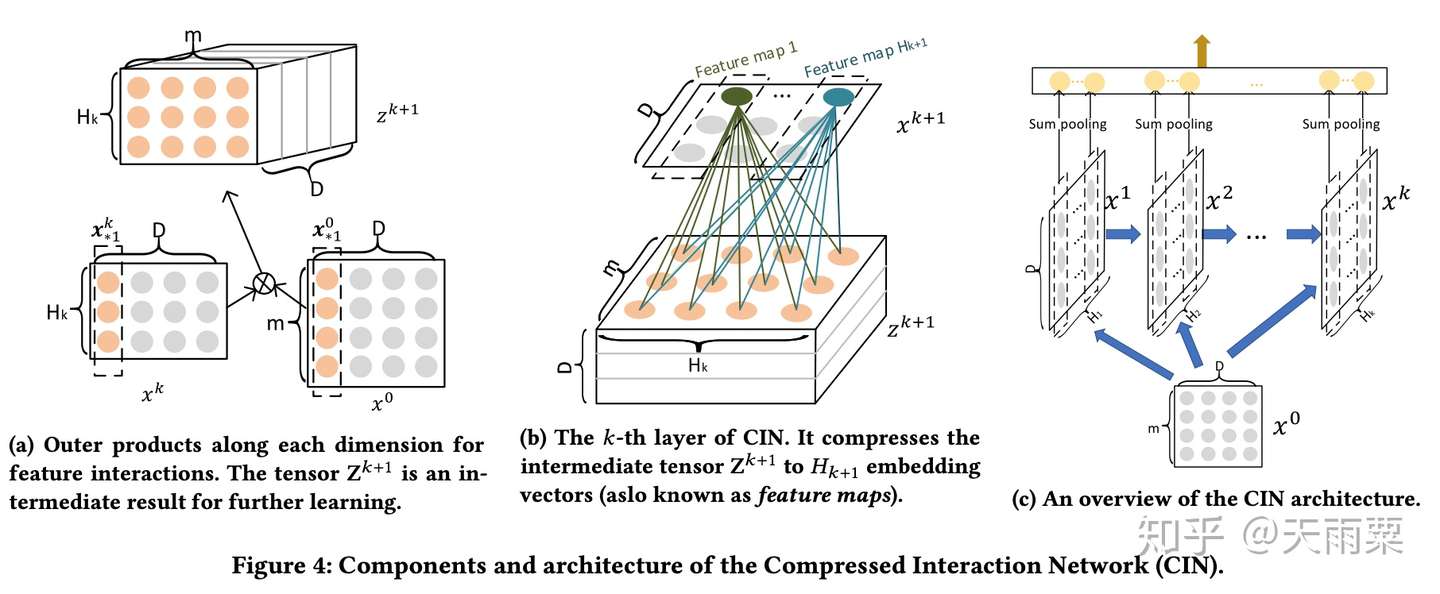
可以看出 CIN 在计算上相对比较复杂,但是由于 CNN 参数共享机制以及 sum pooling 层的存在,CIN 部分的参数规模与特征的 Embedding size 大小 是无关的。假设输入 field 有
个,共有
层,每层有
个 feature map,那么 CIN 部分的参数规模为
。
但是在时间复杂度上,CIN 存在很大劣势,CIN 的时间复杂度为 。
优势:
- xDeepFM 可以同时学习到显式的高阶特征交叉(CIN)与隐式的高阶特征交叉(DNN)
- 在交叉特征的学习上,CIN 采用了 vector-wise 的交叉(而不是 DCN 中的 bit-wise 交叉)
不足:
- CIN 在实际计算中时间复杂度过高
- CIN 的 sum-pooling 操作会损失一定的信息
(3)AutoInt:Automatic Feature Interaction Learning, 2019 —— 跨领域 NLP 技术的引入:Multi-head Self-attention 提升模型表达
AutoInt 是 2019 年发表的比较新的论文,它的思路和 DCN 以及 xDeepFM 相似,都是提出了能够显式学习高阶特征交叉的网络。除此之外,AutoInt 算法借鉴了 NLP 模型中 Transformer 的 Multi-head self-attention 机制,给模型的交叉特征引入了可解释性,可以让模型知道哪些特征交叉的重要性更大。
AutoInt 的 Attention 机制采用了 NLP 中标准的 Q,K,V 形式,即给定 Query 词和候选的 Key 词,计算相关性 ,再用
对 Value 进行加权得到结果。
模型结构:
相比于 DCN 和 xDeepFM 采用交叉网络 +DNN 的双路结构,AutoInt 直接采用了单路的模型结构,将原始特征 Embedding 之后,直接采用多层 Interacting Layer 进行学习(作者在论文的实验部分也列出了 AutoInt+DNN 的双路模型结构:AutoInt+)。
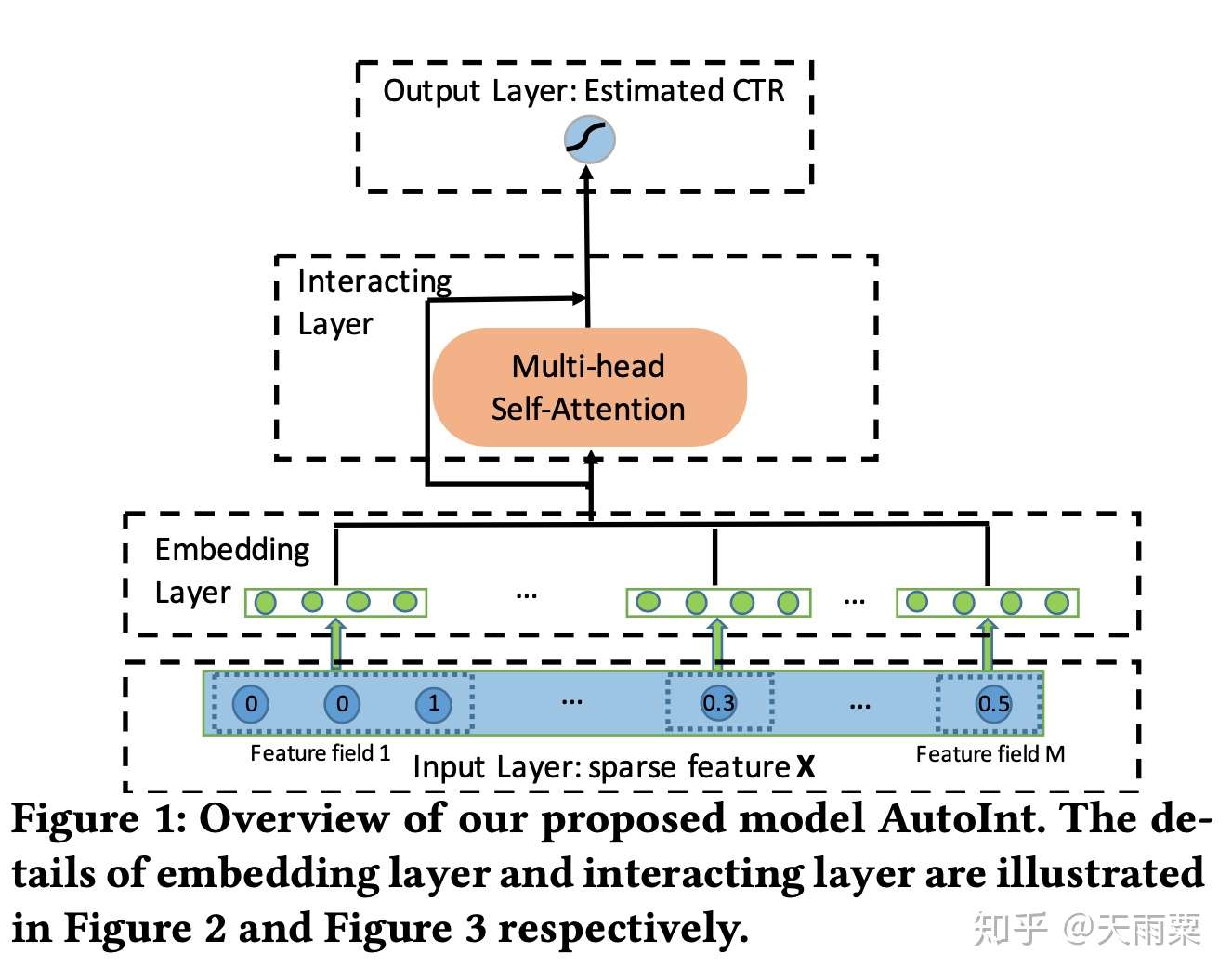
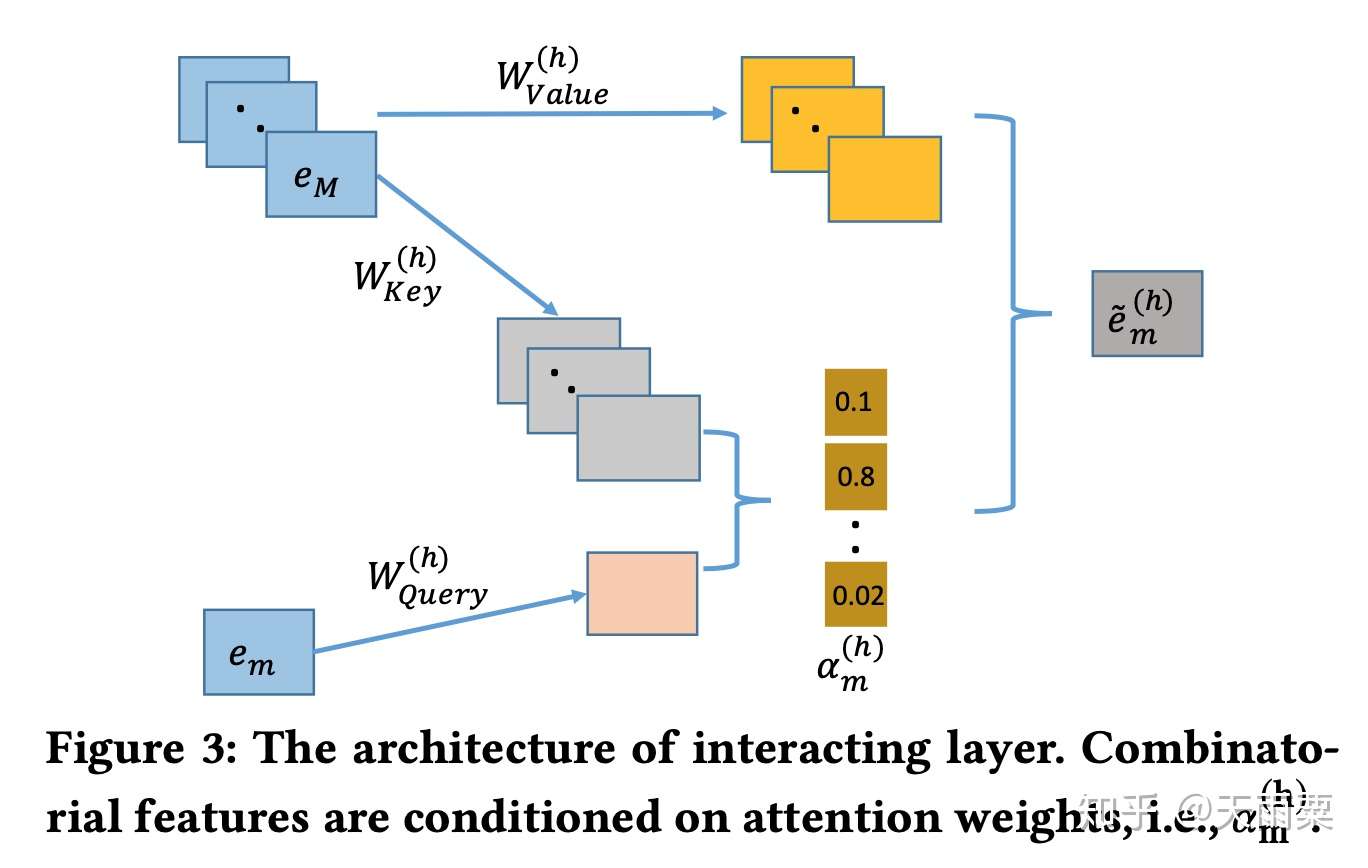
AutoInt 中的 Interacting Layer 包含了两部分:Multi-head Self-Attention 和 ResNet 部分。
在 self-attention 中,采用的是 Q,K,V 形式,具体来说:我们只考虑 1 个 head self-attention 的情况,假设我们共有 个特征,对于输入的第
个 feature embedding 来说,AutoInt 认为它与
个特征交叉后的特征拥有不同的权重,对于我们第
个特征,它与第
个特征交叉的权重为:
其中 ,函数
是衡量两个向量距离的函数,在 AutoInt 中作者采用了简单高效的向量内积来计算距离。得到权重信息后,我们对 M 个特征的 Value 进行加权:
,得到向量 m 与其余特征的加权二阶交叉信息。
进一步地,作者使用了多个 self-attention(multi-head self-attention)来计算不同 subspaces 中的特征交叉,其实就是进一步增加了模型的表达能力。采用 h 个 multi-head 之后,我们会得到 h 个 ,将这 h 个
concat 起来,得到
。
为了保留上一步学到的交叉信息,AutoInt 和 CrossNet 一样,都使用了 ResNet 的思想:
使用 ResNet 可以使得之前学习到的信息也被更新到新的层中,例如第一层原始的 embedding 也可以被融入到最终的输出中。
剩余的特征也以同样的方式进行 multi-head attention 计算,得到 ,将这 M 个向量 concat 之后连接输出层得到最终的预估值。
优势:
- AutoInt 可以显示地、以 vector-wise 的方式地学习有限阶(bounded-degree)特征交叉信息
- 可以以 low interacting layer 学习到 higher-order feature interaction
原文这里给出了一个例子,两层 Interacting Layer 就可以学习到 4 阶特征交叉。定义交叉函数为
, 假如我们有 4 个特征
,第一层 Interacting Layer 之后,我们可以得到
等二阶交叉信息,即两两特征的二阶交叉;将二阶交叉送入下一层 Interacting Layer 之后,由于输入第一层网络融入了二阶交叉信息,那么在本层中就可以得到四阶交叉,如
就可以通过
得到。
- Interacting Layer 的参数规模与输入特征个数
无关。
七。 CTR 预估模型总结与比较
至此我们基本介绍完成了大多数常见的 CTR 预估模型,当然还有 MLR、DIN、DIEN 等其它的模型,由于篇幅限制暂时没有进行介绍。纵观整个 CTR 预估模型的发展过程,我们可以总结出一定的规律,这一部分主要是对上述模型的关系图谱以及特征进行总结。
(1)CTR 预估模型关系图谱
现在我们再回头来看开篇的这张关系图:
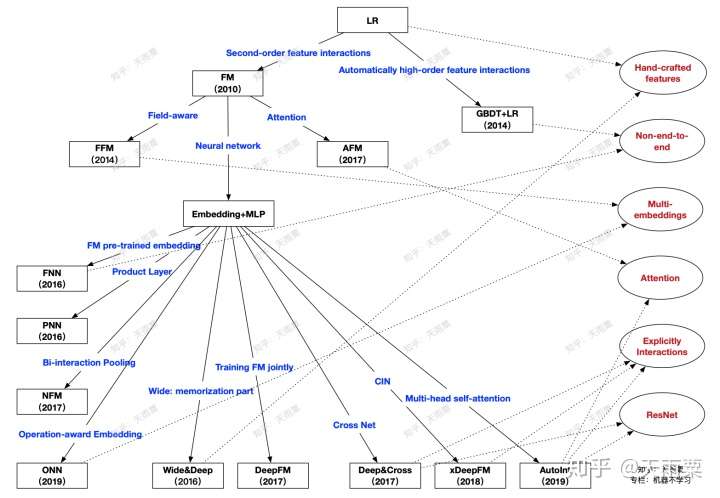
从上往下,代表了整个 CTR 预估的发展趋势:
- LR 的主要限制在于需要大量手动特征工程来间接提高模型表达,此时出现了两个发展方向:
- 以 FM 为代表的端到端的隐向量学习方式,通过 embedding 来学习二阶交叉特征
- 以 GBDT+LR 为代表的两阶段模型,第一阶段利用树模型优势自动化提取高阶特征交叉,第二阶段交由 LR 进行最终的学习
- 以 FM 为结点,出现了两个方向:
- 以 FFM 与 AFM 为代表的浅层模型改进。这两个模型本质上还是学习低阶交叉特征,只是在 FM 基础上为不同的交叉特征赋予的不同重要度
- 深度学习时代到来,依附于 DNN 高阶交叉特征能力的 Embedding+MLP 结构开始流行
- 以 Embedding+MLP 为结点:
- Embedding 层的改造 +DNN 进行高阶隐式学习,出现了以 PNN、NFM 为代表的 product layer、bi-interaction layer 等浅层改进,这一类模型都是对 embedding 层进行改造来提高模型在浅层表达,减轻后续 DNN 的学习负担
- 以 W&D 和 DeepFM 为代表的双路模型结构,将各个子模块算法的优势进行互补,例如 DeepFM 结合了 FM 的低阶交叉信息和 DNN 的高阶交叉信息学习能力
- 显式高阶特征交叉网络的提出,这一阶段以更复杂的网络方式来进行显式交叉特征的学习,例如 DCN 的 CrossNet、xDeepFM 的 CIN、AutoInt 的 Multi-head Self-attention 结构
从整个宏观趋势来看,每一阶段新算法的提出都是在不断去提升模型的表达能力,从二阶交叉,到高阶隐式交叉,再到如今的高阶显示交叉,模型对于原始信息的学习方式越来越复杂的同时,也越来越准确。
图中右侧红色字体提取了部分模型之间的共性:
- Hand-crafted features: LR 与 W&D 都需要进行手动的特征工程
- Non-end-to-end: GBDT+LR 通过树模型提取特征 +LR 建模的两阶段,FNN 则是 FM 预训练 embedding+DNN 建模的两阶段方式,这两者都是非端到端的模型
- Multi-embeddings: 这里是指对于同一个特征,使用多个 embedding 来提升信息表达。包括 FFM 的 Field-aware,ONN 的 Operation-aware
- Attention: Attention 机制为 CTR 预估中的交叉特征赋予了不同的重要性,也增加了一定的可解释性。AFM 中采用单个隐藏层的神经网络构建 attention 层,AutoInt 在 Interacting Layer 中采用 NLP 中 QKV 形式学习 multi-head self-attention
- Explicitly Interactions: DNN 本身学习的是隐式特征交叉,DCN、xDeepFM、AutoInt 则都提出了显式特征交叉的网络结构
- ResNet: ResNet 的引入是为了保留历史的学习到的信息,CrossNet 与 AutoInt 中都采用了 ResNet 结构
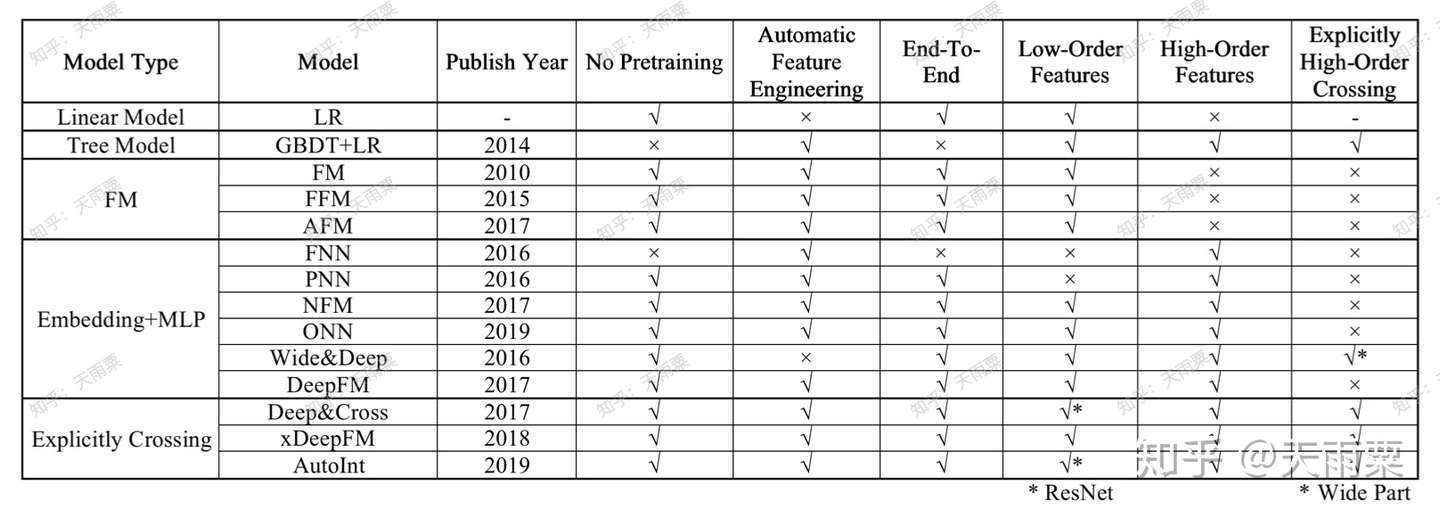
(2)CTR 预估模型特性对比
这里对比主要包含了一下几个方面:
- No Pretraining:是否需要预训练
- Automatic Feature Engineering:是否自动进行特征组合与特征工程
- End-To-End:是否是端到端的模型
- Low-Order Features:是否包含低阶特征信息
- High-Order Features:是否包含高阶特征信息
- Explicitly High-Order Crossing:是否包含显式特征交叉
结语
至此我们对于常见的 CTR 预估模型的演进过程与关系就讲解完毕,纵观整个过程,CTR 预估模型从开始的 LR,到利用树模型自动化组合特征,再发展到端到端的 Embedding+MLP 结构,再到如今越来越复杂的显式交叉网络等,每一次发展都是在不断提升模型对于用户行为的表达与学习能力。CTR 预估不仅是一个数学优化问题,更是一个工程问题,因此如何能够以较低的计算成本,高效地提高模型表达能力将是未来需要努力的方向。
参考文献:
[1] Rendle, Steffen. "Factorization Machines." 2011.
[2] Mcartney, D . "Proceedings of the Eighth International Workshop on Data Mining for Online Advertising."Eighth International Workshop on Data Mining for Online AdvertisingACM, 2014.
[3] Zhang, Weinan , T. Du , and J. Wang . "Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction." (2016).
[4] Product-base Neural Networks for user responses
[5] Xiangnan He, and Tat-Seng Chua. "Neural Factorization Machines for Sparse Predictive Analytics."the 40th International ACM SIGIR ConferenceACM, 2017.
[6] Yang, Yi.et. "Operation-aware Neural Networks for User Response Prediction.".
[7] Juan, Yuchin, Lefortier, Damien, and Chapelle, Olivier. "Field-aware Factorization Machines in a Real-world Online Advertising System.".
[8] Xiao, Jun, Ye, Hao, He, Xiangnan, Zhang, Hanwang, Wu, Fei, & Chua, Tat-Seng. . Attentional factorization machines: learning the weight of feature interactions via attention networks.
[9] Cheng, Heng Tze , et al. "Wide & Deep Learning for Recommender Systems." (2016).
[10] Guo, Huifeng, Tang, Ruiming, Ye, Yunming, Li, Zhenguo, & He, Xiuqiang. . Deepfm: a factorization-machine based neural network for ctr prediction.
[11] Wang, Ruoxi, Fu, Bin, Fu, Gang, & Wang, Mingliang. . Deep & cross network for ad click predictions.
[12] Lian, Jianxun, Zhou, Xiaohuan, Zhang, Fuzheng, Chen, Zhongxia, Xie, Xing, & Sun, Guangzhong. . Xdeepfm: combining explicit and implicit feature interactions for recommender systems.
[13] Song, Weiping, Shi, Chence, Xiao, Zhiping, Duan, Zhijian, Xu, Yewen, & Zhang, Ming et. . Autoint: automatic feature interaction learning via self-attentive neural networks.