作者 | lhy12138
导读
目前百度大搜主要有基于稀疏表征的倒排检索和稠密表征的语义检索双路召回。随着深度学习技术的发展,语义检索的召回效果得到了显著提高;与此同时,因为稀疏表征有着精确匹配、索引效率和可解释的优势,最近学术界重新将目光放回稀疏表征架构,研究稀疏表征如何从大规模语言模型中获益。本文将介绍学术界在倒排召回和语义召回的最新进展。
全文6386字,预计阅读时间16分钟。
一、搜索中的召回
召回一般会从海量候选库中选择与query相关的文档送给上层排序模块,因为效率原因,往往无法执行query-url细粒度交互。目前召回主要有基于term的传统倒排召回和基于向量表征的语义召回。本文将介绍两个方向在学术届的一些最新进展。
二、如何看待语义召回和传统倒排召回的关系?
随着预训练模型和样本技术的更新,语义召回表现了强大的检索效果,而传统倒排技术因为成本、效率问题并没有获得效果的显著提高。倒排召回基于term归并,因此具有较强的可解释性;而语义召回在向量空间搜索与query语义最相似的文档,对语义的表达能力更强。应该如何看待两者在召回链路上的关系呢?
Are We There Yet? A Decision Framework for Replacing Term Based Retrieval with Dense Retrieval Systems
这篇论文提出了一套框架,包括一组指标(不仅从效果出发),彻底比较两个检索系统。
主要标准 (效果/成本) 以及 次要标准 (robustness):
次要标准:子问题集合的效果(如长度在某个范围的q、频率在某个范围的q、lexical匹配的能力、模型的泛化能力、决策显著差异比例、甚至是系统可维护性、未来迭代空间、成本)
最终论文在一个检索评估集上给出了相应的结论:即在向量化成本可接受的前提下,语义召回系统可以替代倒排召回系统。而在实际工业界对应的问题往往更为复杂,但论文提出的分析框架正是我们需要重新审视和思考的内容。
BEIR: A heterogenous benchmark for zero-shot evaluation of information retrieval models
这篇论文对学术界现有检索相关数据集进行汇总,从各个领域汇总了不同下游任务中对检索能力的需求,以全面地评估现有召回模型的效果。


从表格可以看到一些有意思的结论:在zero-shot的场景下,BM25是一个非常健壮的检索系统。基于term细粒度语义交互的两种方法(colbert/BM25+CE)仍然表现了一致的优越性。但稀疏表征和稠密表征的双塔模型似乎表现不佳。同时观察到doc2query是一个稳定的提升,因为它只会扩展词,更像是对BM25的合理性改动,检索方式和打分逻辑与BM25一致。
同时作者也提到,数据集存在词汇偏差问题:标注候选来自于BM25检索,因此可能对不依赖词汇匹配的模型存在好结果的漏标注问题,对新召回结果标注后:

其中语义召回模型(如ANCE)指标显著提高。
通过以上两篇论文发现,不管是倒排召回还是语义召回在不同场景下有着自己独立的优势,因此我们在后文会针对两个方向分别介绍相关进展。
三、倒排召回新发展
如果想通过现有技术促进倒排发展,我们有哪些可以尝试的方案?
最新进展:
可学习的稀疏表征(将query分析、doc理解以及检索匹配融合成端到端任务,但以稀疏向量分别表示query和doc),仍然依托倒排的检索方式,因此保留倒排的优势(可解释、term匹配能力强),同时进一步提升语义泛化能力。
SPLADE: Sparse lexical and expansion model for first stage ranking
稀疏表征:用整个词表重新描述doc,同时实现对term weight和term expansion。

可以看到,最终每个文档被描述为term和score的形式,同时会删除文档已有冗余词和增加相应扩展词。
稀疏表征和预训练任务中mask language model任务很像,将每个token经过transformer表示后最终还原到词表信息中,因此稀疏表征复用了mlm任务的head。
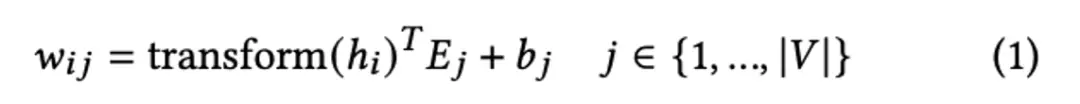
通过汇总(pooling)原始query/doc中的所有稀疏表示,将query/doc表示成一个词表维度的稀疏向量,并且引入flops正则来控制扩展term的数量。同时在稀疏表征的基础上通过点积的形式计算q-u匹配得分。
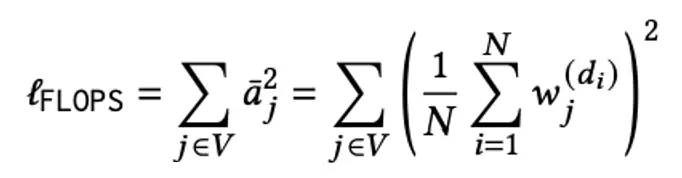
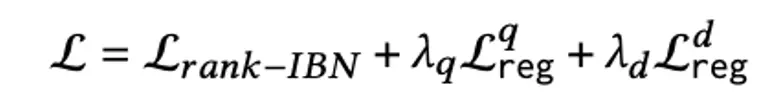
最终loss表示为常见的in-batch CE loss和相应flops正则loss。

From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective
本文是验证在稠密表征(对应上文提到的语义召回模型)下提出的各种优化思路是否可以迁移到稀疏表征中:
包括:蒸馏技术(margin-mse)、难样本挖掘技术(单塔挖掘hard-neg)和预训练技术(cocondenser强化cls能力)。

最终通过实验证明了,多种方法均可迁移到稀疏表征场景下。
SpaDE: Improving Sparse Representations using a Dual Document Encoder for First-stage Retrieval
出发点:相比统一建模term weight和term expansion,采用双编码器独立建模,同时提出联合训练策略来彼此促进。

将整个模型结构拆分三部分:
query端:为了提高query端inference效率问题,只采用了分词器,即仅有one-hot信息。
doc端term weight模块:预测term的权重。

doc端term expansion模块:预测top-k扩展词及权重。
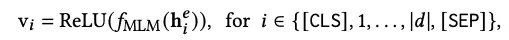
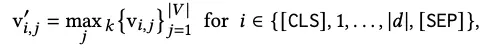
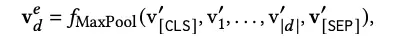
最终汇总doc端的整体稀疏表征:
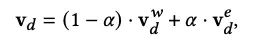
同时提出了协同训练策略:
作者观察到联合训练(先获得最终merge的表征vd后直接进行训练)几乎没能带来效果的增益。
因此模型采用协同训练方式:

热启阶段 :使用不同的目标函数独立训练两个doc端编码器。
term weight :正常的in-batch loss来刻画query和doc的相关性分数。
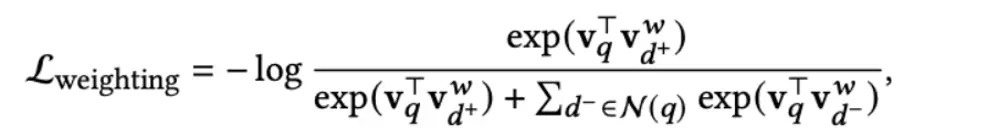
term expansion:因为query没有进行扩展,因此如果doc未能扩展出query词则对应query
词不会获得相关性分数,因此期望扩展词尽可能扩展到query且尽量不要扩展非query词。
因此增加了单独的约束项,在标准召回loss的基础上,强化了query稀疏表征和doc稀疏表征在词命中上的能力,尽可能的要求doc能扩展出query所需的扩展词。

finetune阶段 :每个编码器为对方提供topr%的大损失样本,强化互补性。(权重模型的大损失样本可能是词汇不匹配,而扩展模型的大损失样本可能是当前模型对weight刻画较差)

LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval.
出发点:认为MLM并不适合做稀疏表示,mlm倾向于为低熵的单词分配高分,而稀疏表示能希望关注对语义重要的高熵词。(mlm 的loss更极端一些,只去预测原词,且更容易mask到低熵词,而稀疏表征则希望这个预测的值更soft以体现term重要性+扩展词能力)
因此提出了以下框架,包括三个组件:
- Encoder(BERT)
- 词典瓶颈模块
- 弱mask解码器

Encoder:输入文本经过一定比例mask后,在MLM-head的输出即为稀疏表征。
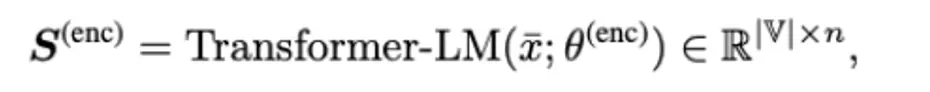
词典瓶颈模块:利用doc的稀疏表征a来获得句子稠密表征b。
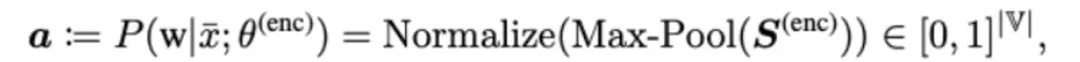
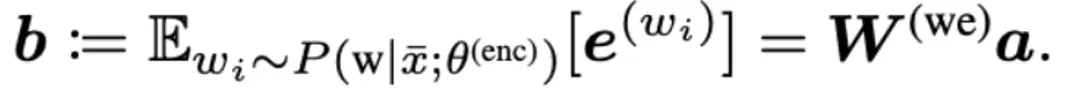
其中W是原始BERTword embedding表示。
弱mask解码器:利用稠密表征b来还原mask信息,用b替换CLS,通过两层decoder还原被mask的词。(希望稀疏表征承担CLS相应的信息能力,在预训练阶段强化稀疏表征的表达能力。)
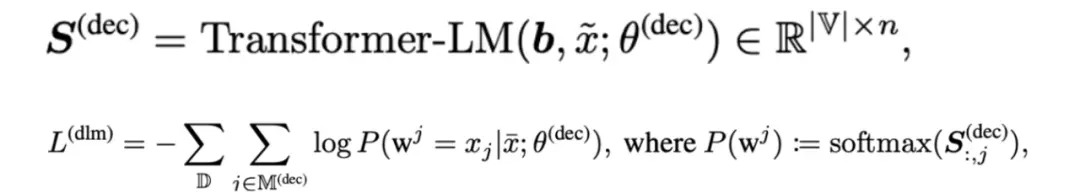

四、语义召回新发展
语义召回虽然具有强大的语义能力,但在实践中仍然存在以下几类问题(包括但不限于):
- 单表征信息表达能力弱。
- 无法对精确匹配进行建模。
- 多表征如何保证表征的有效性
单表征信息压缩问题:
Simlm: Pre-training with representation bottleneck for dense passage retrieval.
出发点:
减少预训练和finetune的不一致,提高样本效率,希望cls尽可能编码doc中的信息。
做法:
1.随机mask两遍原始序列,利用生成器还原两个新的序列。
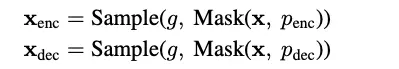
2.对于enc序列,利用多层transformer编码,获得句子级别CLS表示,其中loss约束为当前词是否发生过替换。
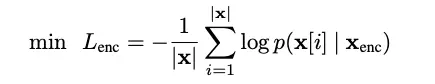
3.对于dec序列,使用2层transformer编码编码整个序列及enc序列的句子表示,同样loss约束为当前词是否发生过替换。

由于dec序列仅使用2层transformer,因此迫使句子级别cls信号需要捕捉原始enc序列更多的语义信息。

精确匹配问题:
Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?
出发点:dense retrieval在词语匹配和低频实体不如稀疏方法,希望能具有稀疏模型的词汇匹配能力,模拟稀疏retrieval。
思想:利用稀疏teacher蒸馏到dense retrieval(模仿模型),再和正常的dense retrieval concat。

实践经验:
- 稀疏teacher蒸馏到模仿模型时,mse和kl loss未能起作用。最终使用稀疏teacher来生成pos和neg,使用常规对比损失来做样本级蒸馏而非soft-label蒸馏效果更佳。
- 同时尝试将模仿作为dense的热启模型,但效果一般,因此选择两个表示联合训练,尝试了求和/concat以及freeze模仿模型只更新dense模型和加权系数的方案。

同时作者验证了模仿器是否真的学到了词汇匹配的能力,发现模型器与BM25排序一致性有大幅度提高。

LED: Lexicon-Enlightened Dense Retriever for Large-Scale Retrieval
出发点:缺少term匹配和实体提及的局部建模
思路:
- 增加lexical的难负样本同时更新lexical模型和dense模型。(lexical模型为上文讲过的SPLADE模型)
- 相比KL损失loss,只要求弱监督保证rank一致性。
(思路和上篇论文比较一致,想用一个更好的词汇模型来把知识集成到dense模型上)


多表征建模问题:
Improving document representations by generating pseudo query embeddings for dense retrieval
出发点:单表征需要压缩文档的全部信息,可能是次优的
(背景前提:部分评估集doc会根据内容提取多个问题,先天有多query需求)
解决思路:拿到所有token的最终表征,执行k-means聚类,然后从每个doc中提取多个表征。
K-means算法:找到doc全部token的聚类中心(初始化:随机选择token表示或对doc切割按等间距选择)
最终收敛多个step后,所剩的聚类中心认为反应了”潜在的”query查询。
训练阶段:k-means获得多个聚类中心,query对doc的多个聚类中心做attention,再点积算分数。
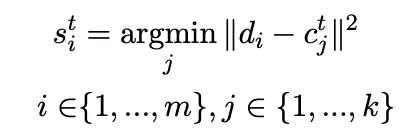
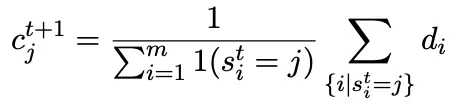
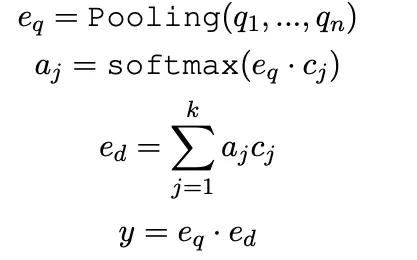
推理阶段:先单独执行一次ann查询,找到top-k个候选,再利用对应doc的全部表征计算attention表示及重排序分数。

Multi-View Document Representation Learning for Open-Domain Dense Retrieval
出发点:doc需要多表征,希望doc中的某一个表征和query实现对齐以及发现MEBERT中多个表征会退化到[CLS]。
思路:用多个[viewer]替换掉[cls],用作文档多表征,同时提出局部均匀损失+退火策略匹配不同的潜在查询。


退火策略:
一开始温度系数较大,softmax后分布均匀,每个viewer向量都能获得梯度,每个epoch后调整温度系数以突出真正匹配的视图。
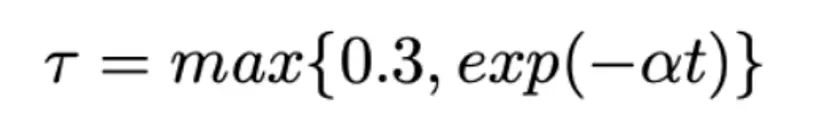

Learning Diverse Document Representations with Deep Query Interactions for Dense Retrieval
出发点:多文档可能被多个潜在query查询,直接doc2query能否模拟潜在交互。
思路:使用生成的查询来学习文档表示,T5 finetune doc2query,并decode10个query。

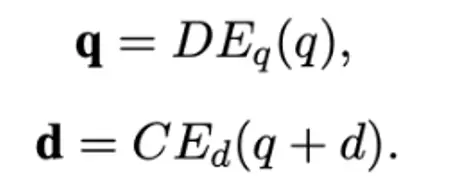
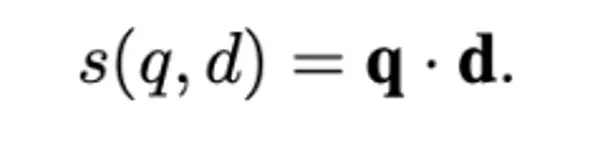
只对所有正样本执行doc2query,并将生成的query作为难负样本的query信号
Hard neg:
正样本:(q+ d+)负样本(q+ d-)防止模型靠query端走捷径,强调doc信息
In-batch neg:
正样本:(q+ d+) 负样本(其他q+ d-)学习topic信号
推理:生成多个query来表示doc的多表征,与doc拼接送入doc端双塔模型。


除了上文提到的三个问题,语义模型还存在以下问题(包括但不限于),但受限于篇幅未能在这次分享中介绍:
- 语义模型蒸馏技术
- 基于实体的(多)表征技术
- 语义模型建模多目标场景
五、总结
以上,我们总结了近期学术界在倒排和语义召回两路的最新进展,可以看到随着大规模预训练模型的发展,不管是倒排还是语义召回的能力均可以从中获益。