
分享嘉宾:陈戊超、高赟 阿里 技术专家 文章整理:有感情的打字机 内容来源:Flink Forward ASIA 出品平台:DataFun
导读: Flink 是一个分布式计算引擎,支持批流一体的数据处理。在实际生产中的人工智能使用场景中,Flink 在包括特征工程,在线学习,在线预测等方面都有一些独特优势,为了更好的支持人工智能的使用场景,社区以及各个生态厂商都做了一些工作,本文将重点介绍近期 Flink 在人工智能生态系统中的工作进展。
主要内容包括:
- Flink 构建 AI 系统的背景
- Flink ML Pipeline 和算法库 Alink
- 分析和 AI 的统一工作流(AI Flow)
- Flink 在流运行模式下迭代的架构设计
首先向大家介绍 Flink 构建 AI 系统的背景。
1. Lambda 架构及批流统一数据处理
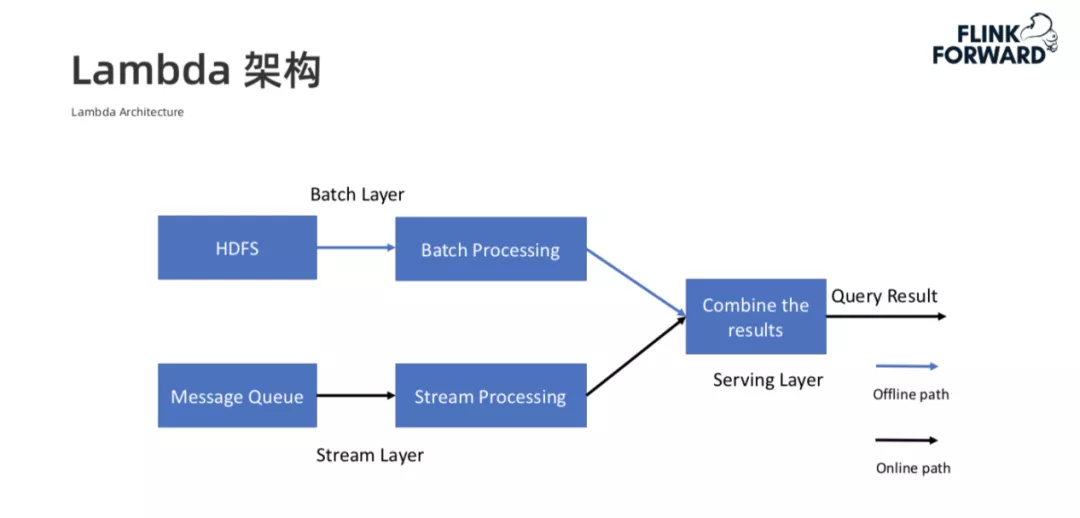
Lambda 架构是大数据处理领域中一种典型的架构。如上图所示,图中上方蓝色线代表的是离线批处理的数据流,下方黑色线代表的是实时流模式的数据流。为了兼顾整个大数据处理中的吞吐和实时性,我们通常会将离线的数据处理和实时的数据处理结果进行合并后对外提供服务。

在 Lambda 架构里,在离线数据处理和实时数据处理过程中,我们会用到两种不同的计算引擎,同时维护两份代码。但这两个流程对数据的处理逻辑其实是一样的,这样会导致两个问题:
① 维护代价高 ( 包括代码的维护代价,及不同的计算引擎对部署的维护代价 )
② 很难保证在线离线处理逻辑一致
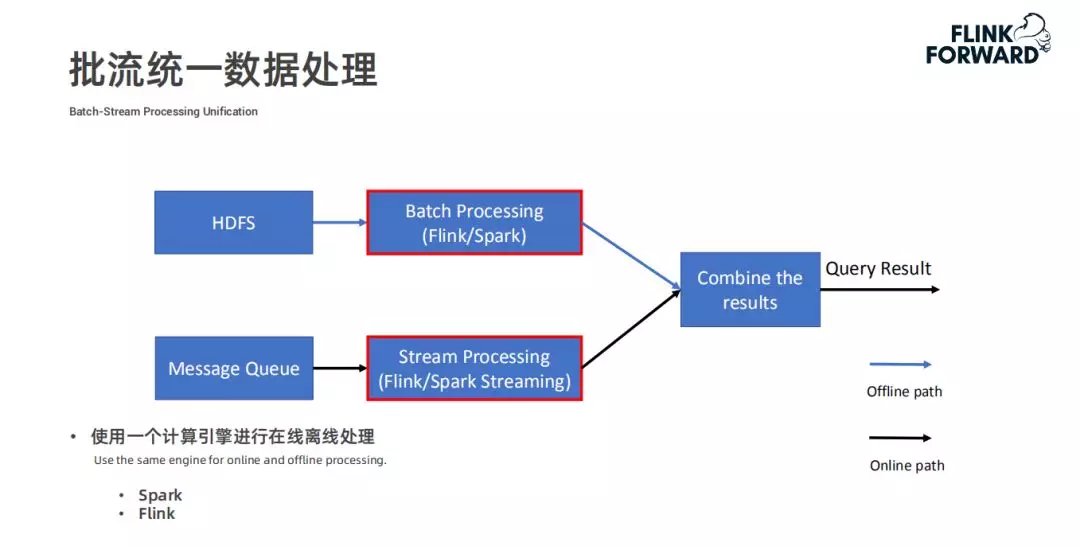
为了解决这两个问题,实现批和流的数据统一,就有了 Flink 和 Spark。Flink 和 Spark 都可以处理批数据,对流数据的处理可以由 Flink 和 Spark streaming 来完成。这样就避免了上述维护两套代码和两套系统及逻辑一致性的问题。
2. 机器学习在线离线处理
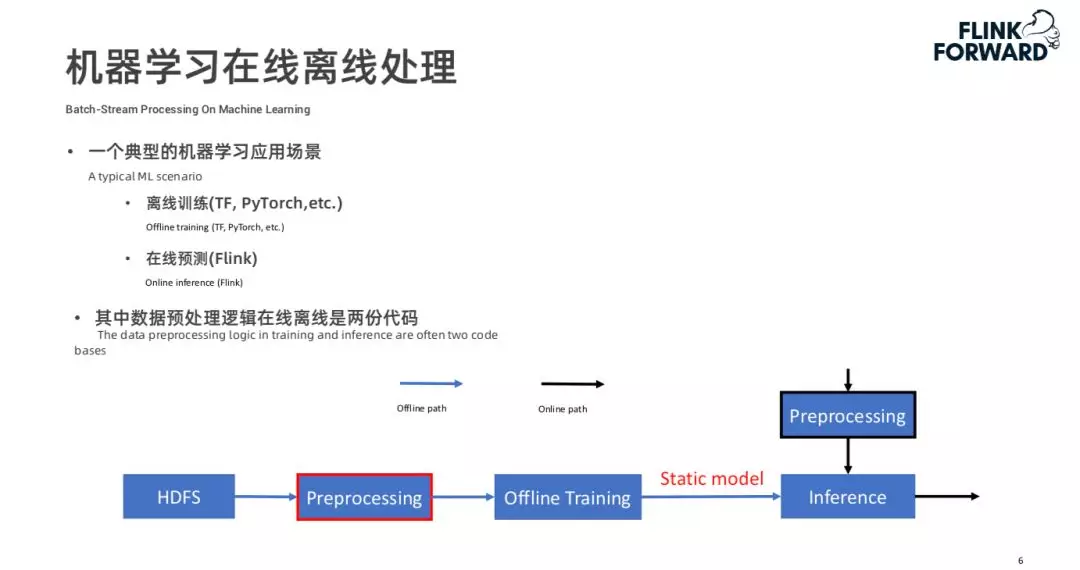
在机器学习场景下,在线离线处理也会面临一些问题。上图是一个典型的机器学习处理过程。首先会将离线的数据进行预处理和特征工程(如红框标注所示),然后进行离线的模型训练,训练好的模型会推到线上做推理。推理模块加载模型后,在线的数据也会有进行预处理和特征工程的过程,将处理之后的数据喂给模型做在线推理。
这样的过程也会面临如上述大数据处理中的问题,我们同样会维护离线的数据处理和在线推理的数据处理两份代码。
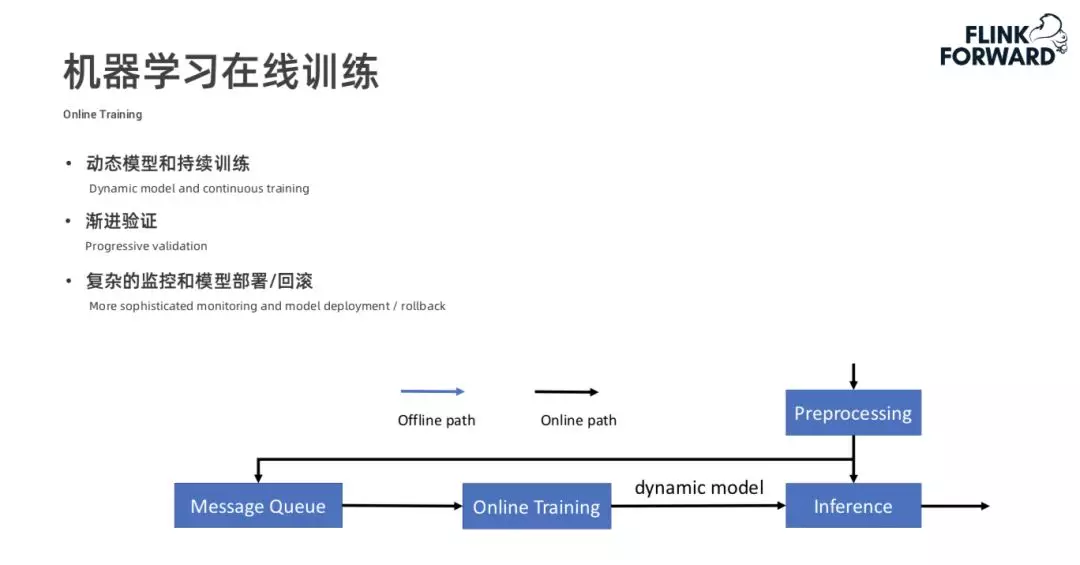
在机器学习领域除了离线的模型训练以外,还有在线的模型训练。如下图所示,我们通常会将预处理的数据写到一个 Message Queue 中(如 Kafka),然后进行 Online training,training 的过程是持续不断的,期间会不断的产生动态的模型,然后推送给在线的推理模块进行推理。在线的机器学习的特点就是模型的动态更新、持续训练和不断验证。同时需要比较复杂的模型监控,模型部署和模型回滚等策略。
于是就产生了机器学习中的 Lambda 架构:
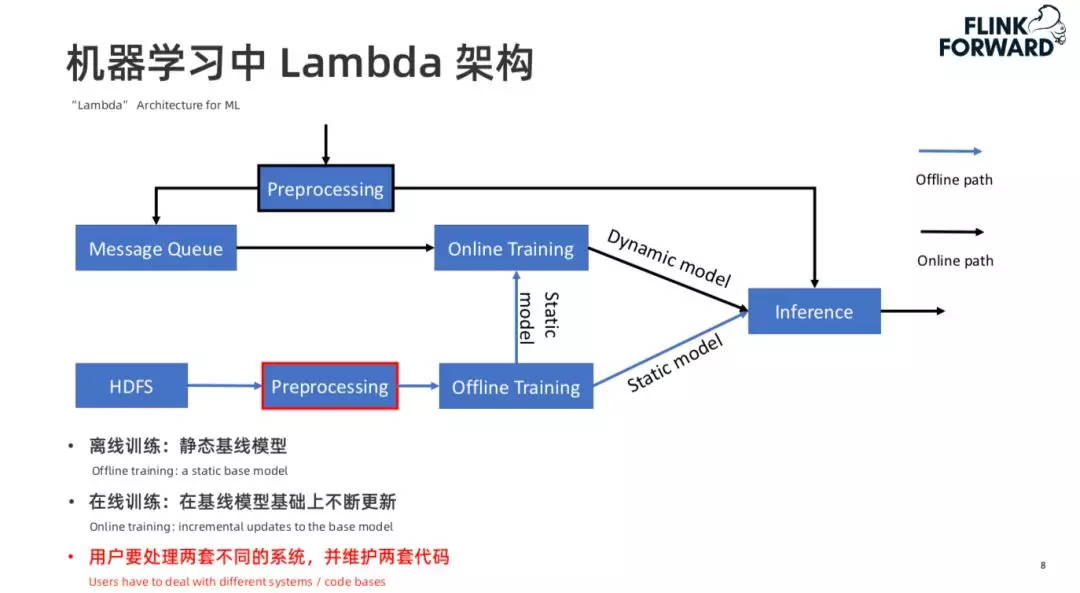
一般来说,在线的模型训练并不是从头训练一个模型,而是通过离线训练出一个基准的模型,然后推给在线,在线流程再在这个基准模型上进行在线的训练。这样同样存在离线和在线两份代码,涉及两套不同的系统。也会增加维护的复杂度。
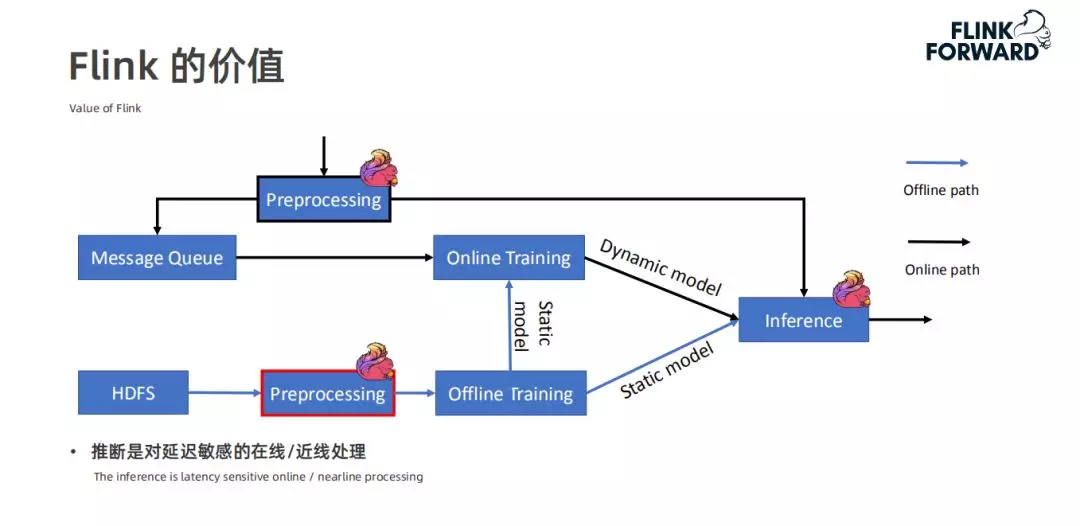
那么 Flink 在这套架构中有什么样的价值。Flink 是天生支持批流一体的计算引擎,在在线机器学习领域的预处理过程中,我们很自然地会使用 Flink 进行数据处理,在离线的机器学习训练中也可以使用 Flink 进行批次的预处理。同时,在在线推理的过程中,也会使用 Flink 进行推理(因为推理是一个对时间比较敏感的过程)。所以 Flink 在机器学习 Lambda 架构中的价值体现在在线的数据的预处理,离线数据的预处理,在线的推理。
所以是否能将机器学习中的 Lambda 架构进行批流统一?
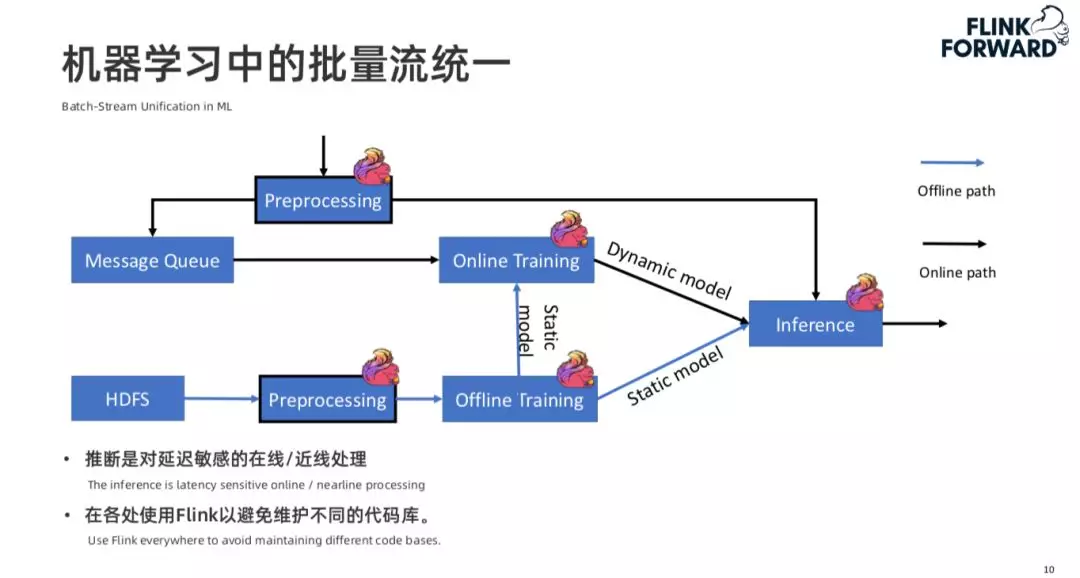
如上图所示,除了数据处理和推理可以使用 Flink 外,Online training 和 offline training 的过程也可以用 Flink 计算引擎替代。这样做的好处一是,用户只需要写一份代码就可以同时实现在线和离线的训练,并且避免了逻辑的不一致性和维护的难度。在线和离线训练中我们通常会使用比如一些深度学习的计算框架比如 TensorFlow 或者 Pytorch 运行在 Flink 上进行模型训练。第二个好处是,我们可以通过使用 Flink 形成一站式的数据处理解决方案。如下图:

在整个数据上,Flink 提供了丰富的接口,包括 SQL,DataStream,CEP,如果再加上 ML 的接口就可以共享整个数据集,不会涉及到不同的系统之间数据拷贝的过程。此外,在将数据打通之后,我们可以使用 SQL,DataStream 这些丰富的 API 来处理数据。
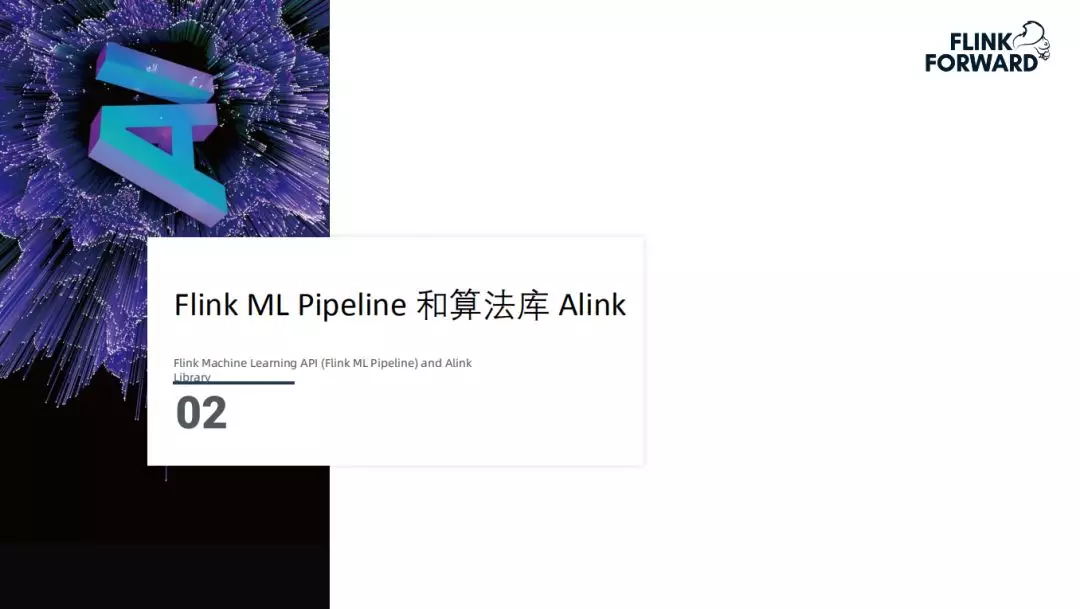
1. Flink AI 生态系统架构
上图是整个机器学习的 Lambda 架构图。对应机器学习任务中的不同阶段:首先是数据的管理和获取阶段(Data Acquisition),在这个阶段 Flink 提供了非常丰富的 connector(包括对 hdfs,Kafka 等多种存储的支持),Flink 目前还没有提供对整个数据集的管理。下一个阶段是整个数据的预处理(Preprocessing)及特征工程部分,在这个阶段 Flink 已经是一个批流统一的计算引擎,并且提供了较强的 SQL 支持。之后是模型训练过程(Model Training),在这个过程中,Flink 提供了 Iterator 的支持,并且有如 ALink,MLlib 这样丰富的机器学习库支持,且支持 TensorFlow,Pytorch 这样的深度学习框架。模型产出之后是模型验证和管理阶段(Model Validation & Serving),这个阶段 Flink 目前还没有涉足。最后是线上推理阶段(Inference),这个阶段 Flink 还没有形成一套完整的方案。同时形成了 Flink ML Pipeline,以及目前正在做的 Flink AI Flow。
2. Flink ML Pipeline
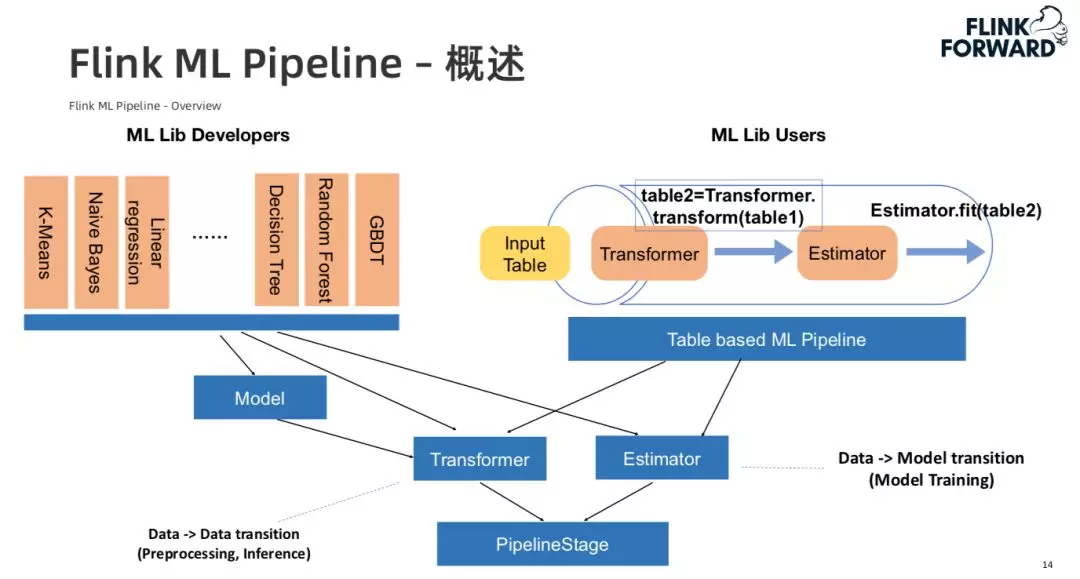
上图是 Flink ML Pipeline 的介绍,该 Pipeline 主要涉及两个抽象,第一个是 Transformer 抽象,是对数据预处理和在线推理的抽象。第二个抽象是 Estimator 抽象,主要是对整个模型训练的抽象。两个抽象最大的差异是 Transformer 是将一份数据转化为另一份处理后的数据,而 Estimator 是将数据进行训练转化为模型。
3. 算法库 Alink
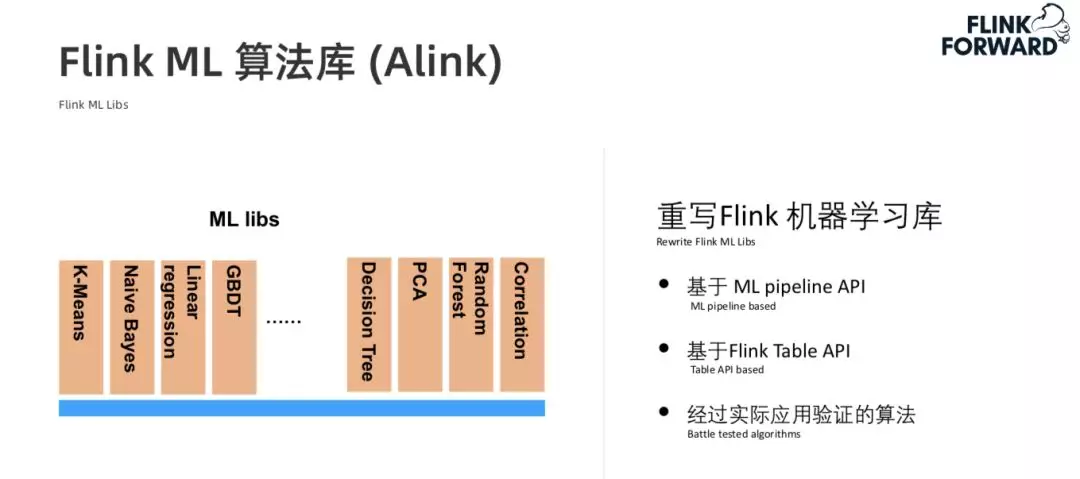
Alink 主要是重写了 Flink 中很多机器学习库。其有两个重要的特点,一是 Alink 是基于 Flink 的 ML Pipeline。第二是基于 Flink Table API。Flink Table API 天然就是批流统一的。
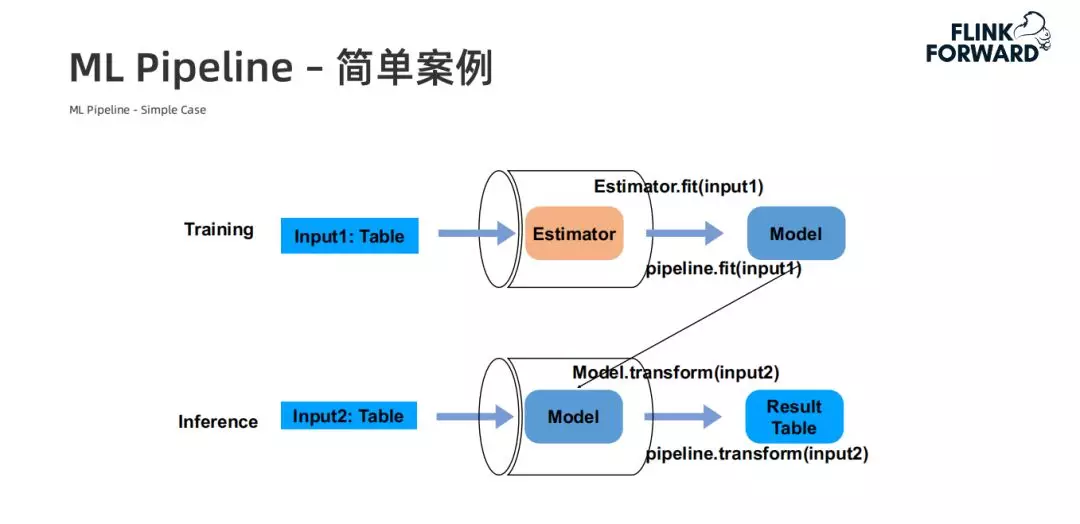
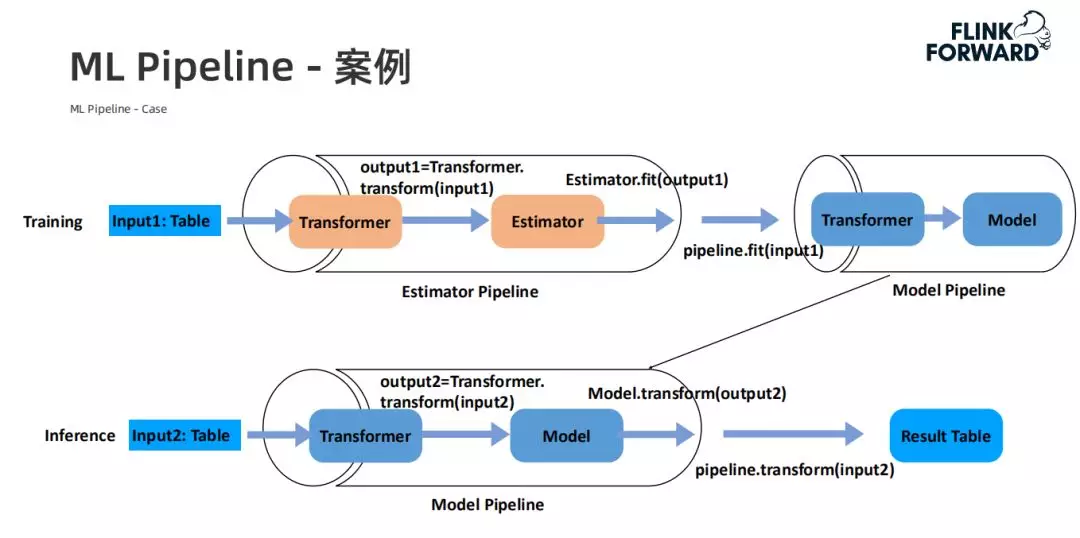
ML Pipeline 简单案例:
4. ML Pipeline 价值
Flink ML Pipeline 最大的价值在于为最终用户统一了模型训练和推理的 API,用户只需要关心 Estimator 的 Transformer 里面的逻辑即可。此外,Pipeline 将整个训练过程进行了持久化,确保了训练和推理之间的逻辑一致性,解决了之前 Lambda 架构中维护两份代码可能会导致的逻辑不一致问题。

1. AI Flow 背景
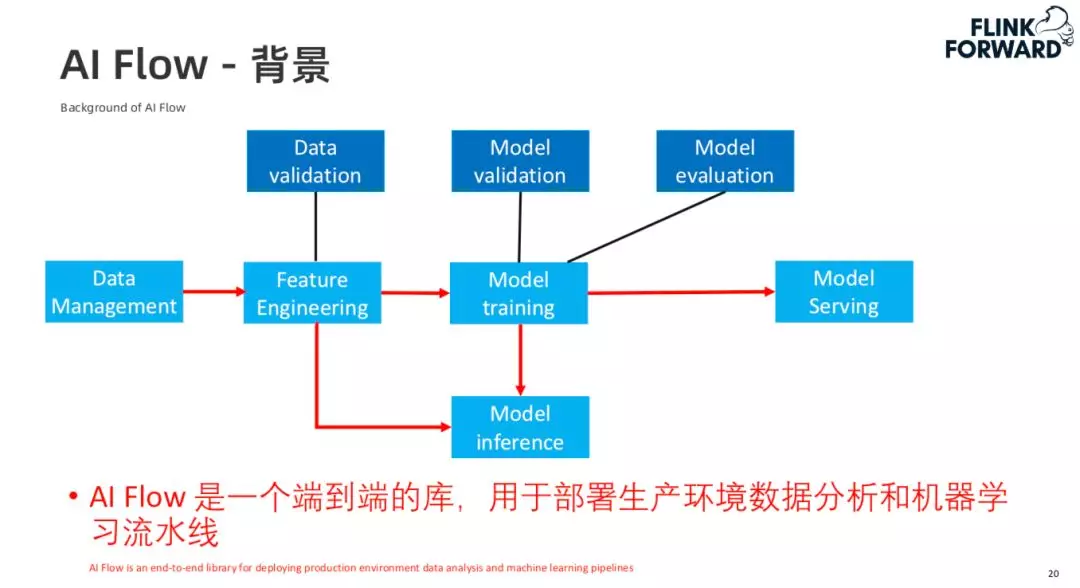
在整个机器学习任务中,有一部分是和模型训练相关的,还有一部分是数据分析,特征工程相关的。因此 AI Flow 的目标是将这整个流程串起来,提供一个端到端的解决方案。
2. AI Flow 概述
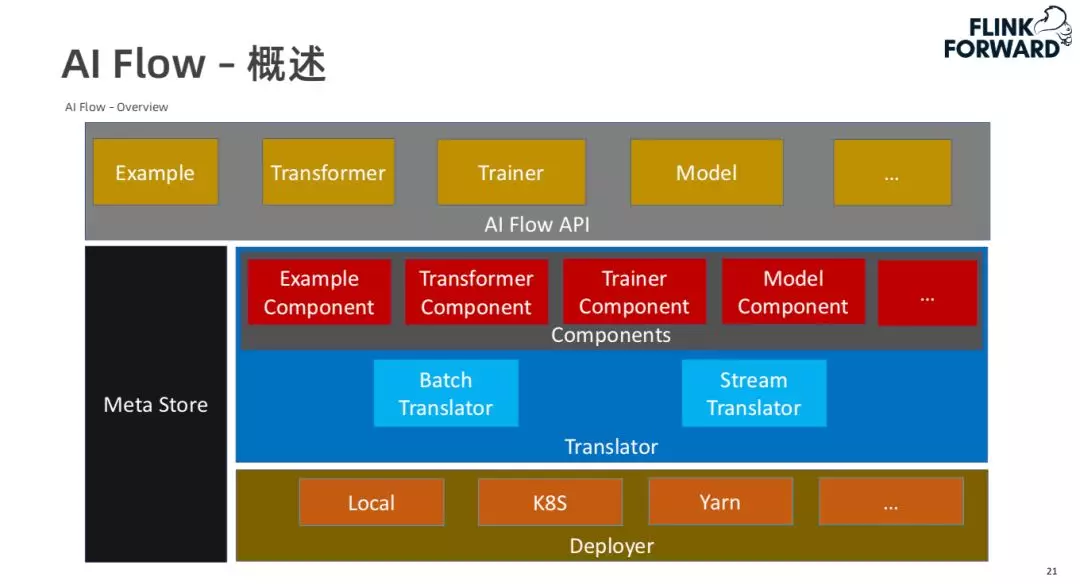
AI Flow 的 API 中包含了 Example(对数据的 API),Transformer(对预处理流程及推理的 API),Trainer(训练流程的 API),Model(模型管理的 API)等。在每个模块中都会产生一些中间 meta 数据,AI Flow 将这些数据存储在 Meta Store 中。这些 API 只是定义了机器学习中的一些处理逻辑,AI Flow 中的 Translator 则将这些逻辑转化为真正可执行的任务。
我们的目标是实现整个机器学习 lambda 架构的批流统一,用户写一份机器学习处理逻辑,可以同时作用于离线的学习过程,同时也可以支持在线的学习过程。Translator 的作用就是将用户通过 AI Flow API 写好的 code 转化为可执行的任务。目前 AI Flow 中包含两类 Translator,第一类是 Batch Translator,第二类是 Stream Translator。在 Translator 中还有一个抽象是 Components,包含与 AI Flow API 相对应的一些 Components。这些 Components 可以对应地解析 AI Flow API 中用户定义的逻辑。通过 Translator 将用户定义好的逻辑处理完之后,通过 Deployer 把生成的任务部署到不同的环境,包括本地环境,K8S,Yarn 等。
3. AI Flow 原理
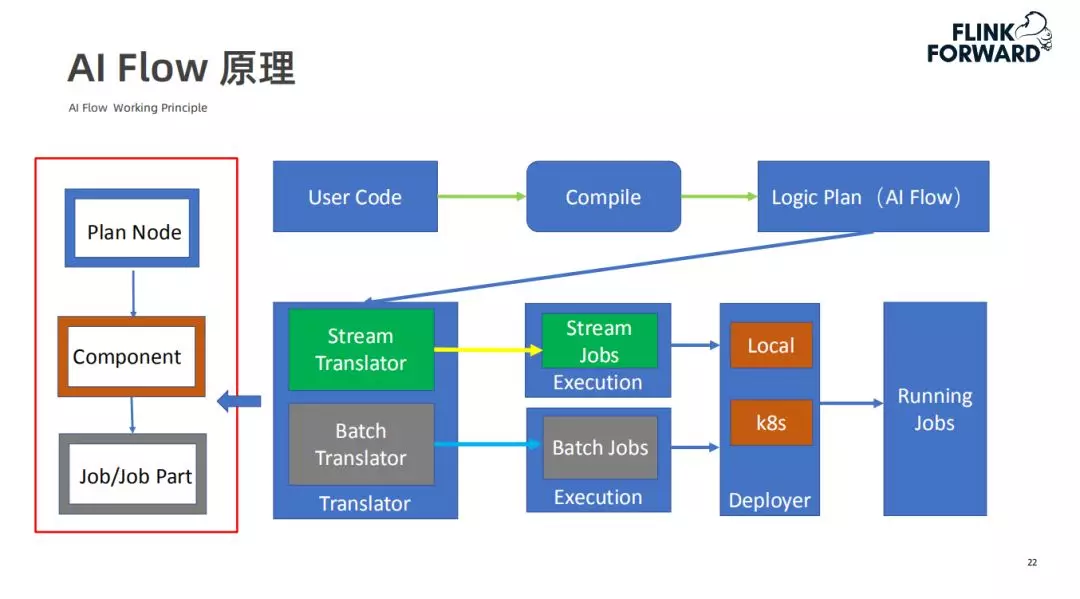
用户通过 AI Flow API 写的代码在编译之后会生成一个逻辑的执行计划,这些逻辑执行计划由很多节点组成,每个节点都有对应的 Translator 中的 Component 解析,解析过程有可能会将其解析为单个的 job,或者一个 job 的一部分(即多个节点生成一个 job)。这个逻辑执行计划会传递给 Translator,如果是流式任务,Translator 会将其翻译为流式的一些 job,同样的批式任务会翻译成批相关的一些 job。之后会将一组 job 组成一个 Execution,传递给 Deployer 通过配置运行在本地,K8S 或 Yarn 上,最后生成一些可以运行的任务。
4. AI Flow 的特点和 Flink AI Flow
AI Flow 提供了用于部署生产环境数据分析和机器学习流水线的端到端的 API,提供了批流统一的数据分析和机器学习工作流 API。具体来说有以下几个特点:
AI Flow:
① 批流统一
② 引擎与平台无关
③ 定义执行组件关系
④ 定义数据集和 IO 格式规范
Flink AI Flow:
① Flink 作为默认分析引擎
② TensorFlow / Pytorch 作为机器学习引擎
5. 图片分类简单案例
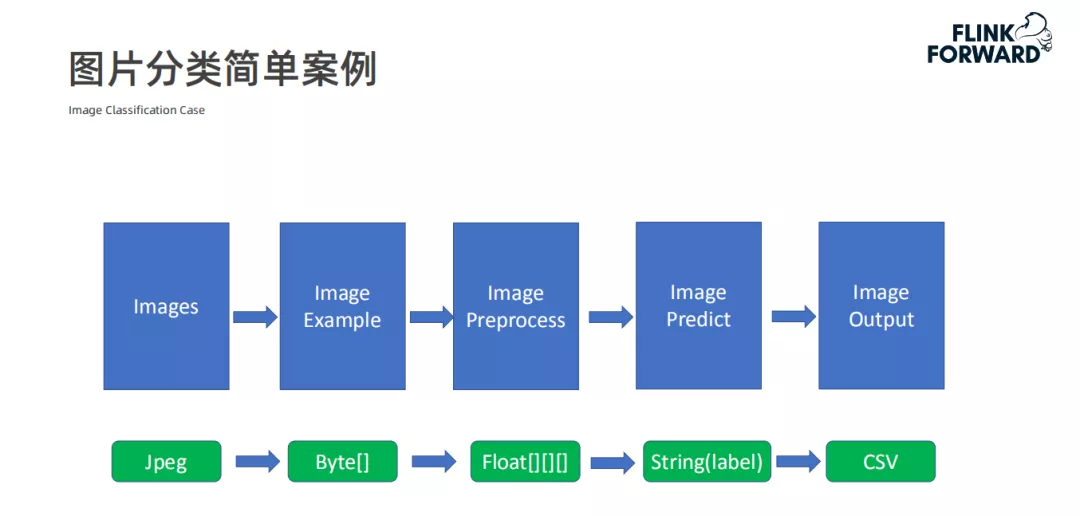
首先通过 Example 对象定义处理前的图片数据,然后通过 Transformer 对象定义预处理过程和模型的预测过程,最后将两个 Transformer 合起来组成一个 Execution 逻辑。

- AI Flow 总结
AI Flow 提供了部署生产环境数据分析和机器学习流水线的端到端 API,同时 AI Flow 还提供了批流一体的数据分析和机器学习工作流 API。
1. 背景与动机
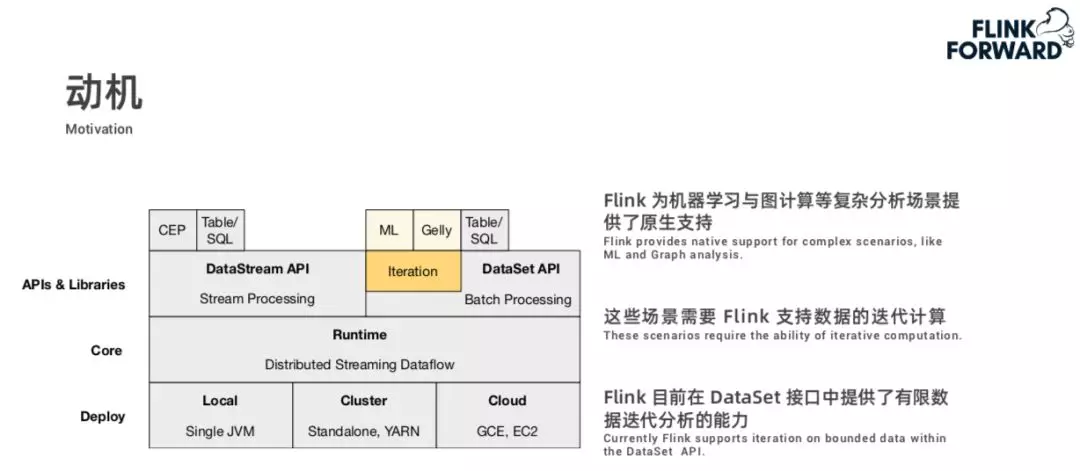
Flink 在机器学习中有一个整体的端到端的框架,目前 Flink 是通过 DataStream 和 DataSet 两套接口分别提供了流处理和批处理的能力。通过前面的讲述,我们可以看到 Flink 流处理和批处理的能力可以用于机器学习的数据预处理阶段。其实除了这些通用的流和批的处理之外,Flink 对于机器学习中的模型训练和图计算这些复杂的分析场景也提供了原生支持。这些场景的特点是对数据的迭代计算要求较高,目前 Flink 对迭代计算的支持主要是在 DataSet 接口部分,因为 DataSet 整体上是一个批处理的接口,所以 Flink 对迭代分析的支持主要是有限数据迭代分析。
例:基于 DataSet 迭代的 K-Means
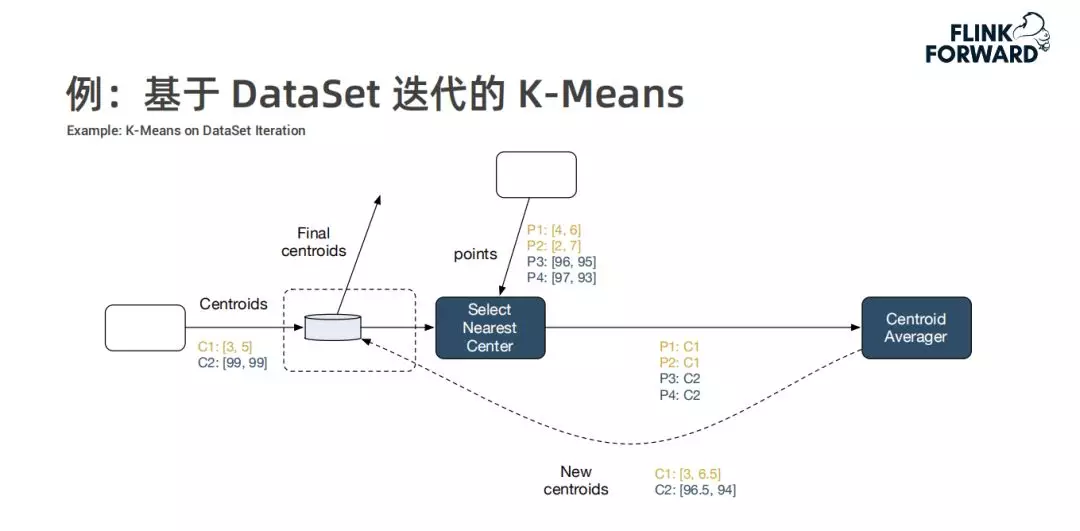
以常见的 K-Means 为例,K-Means 算法的两个输入为待聚类的点和初始类中心,在 DataSet 迭代时,它会在整个计算图中添加一个特殊节点来维护待求中心点当前的结果,在每轮迭代中,对待求中心点进行一次更新(将每个点分配到较近的中心点,之后重新计算中心点,将计算结果通过一个回边发送到维护的待求中心点算子,从而支持超过 DAG 计算能力的处理形式),重复多轮迭代直到收敛,输出最终的中心点。
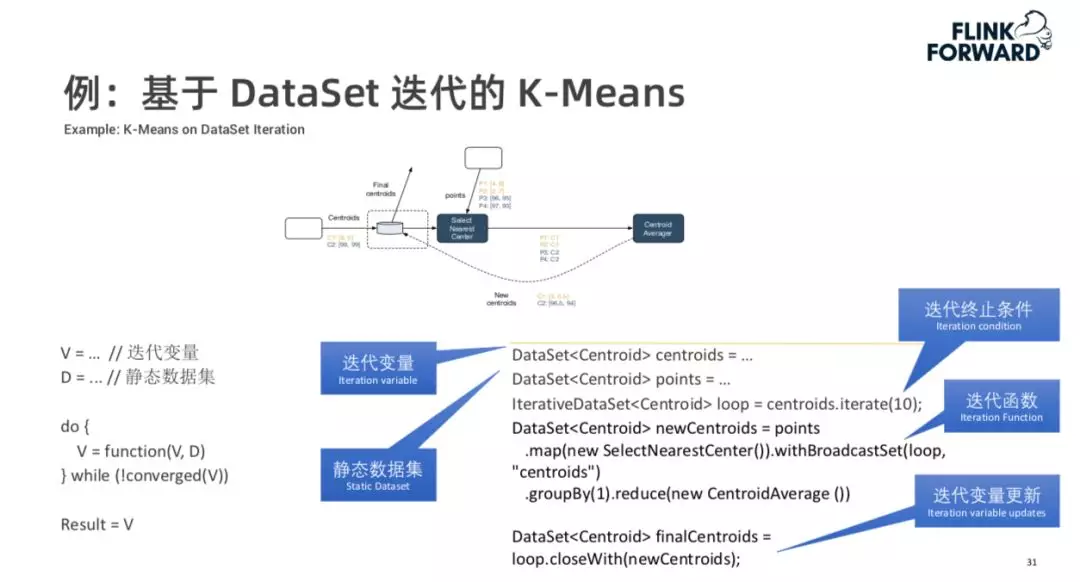
为了表示这种迭代的计算图,Flink 中有几个通用的概念,首先“迭代变量”是在迭代中需要更新的变量,“静态数据集”是在迭代过程中会多次使用但是不会发生变化的数据,在计算过程中该数据实际上只会发送一次,Flink 对该数据做了一个基于磁盘的缓存,在每轮迭代时做了一个重放。他们都是普通的 DataSet 对象,代表来一个有限的数据集,在某一个数据集上调用 Iteration 方法,指定迭代终止条件。Flink 会自动将每一轮的迭代逻辑扩展到所有轮,用户在写迭代逻辑时不需要考虑收到多轮数据的情况。
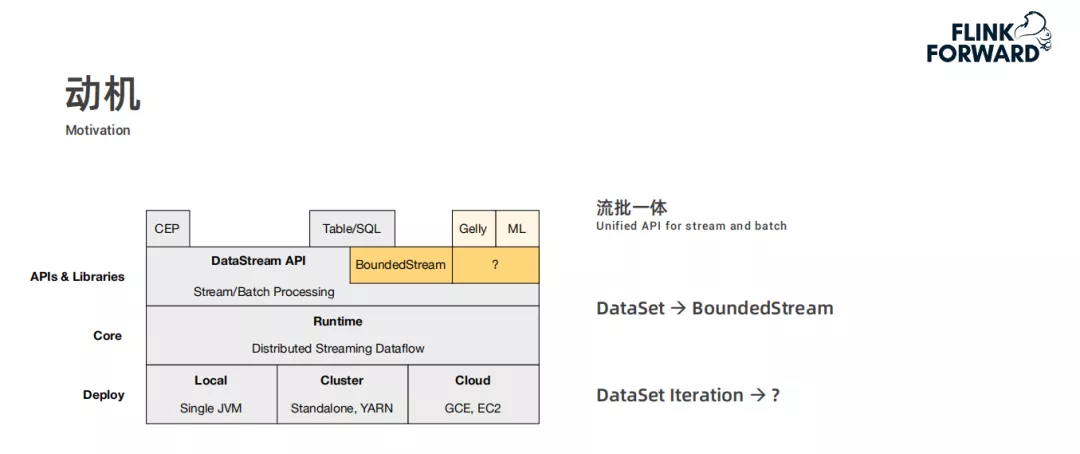
为了实现流批一体,Flink 将批处理的能力从 DataSet 的接口迁移到 DataStream 的接口之上,在 DataStream 接口之上,Flink 会引入一个 BoundedStream 的特殊子类,来实现批处理的能力。相应的,如果把批处理的能力迁移过去,DataSet 的迭代的处理能力也要进行迁移,一个选择是直接平移相应的 DataSet 的实现,但是从前面的介绍可以发现,DataSet 目前的实现有一些问题:

首先它不支持多迭代变量或者嵌套迭代的形式,但是在一些算法(如 boosting 算法)中对这两种迭代也是有需求的。第二点是对于静态数据,Flink 现在是做了一个基于磁盘的重放,在这种情况下,用户是有可能基于业务逻辑做一个更高效的缓存的,但是现在在 DataSet 的迭代上无法实现这一点。最后,在 DataSet 上很难实现针对在线算法的模型训练或者在线流处理的支持。
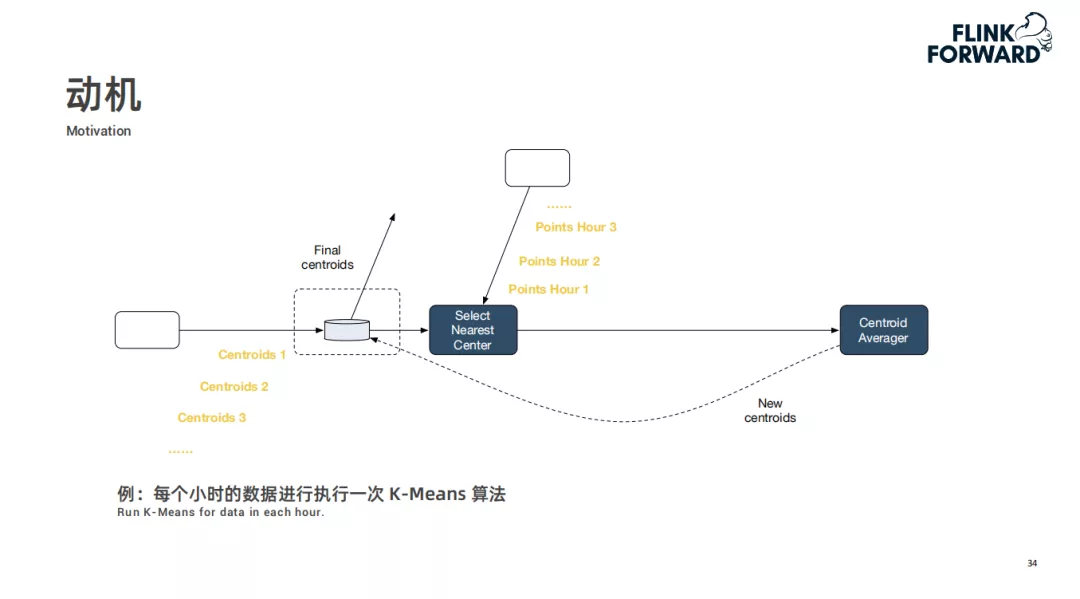
比如使用每一个小时的数据做一次 K-Means。
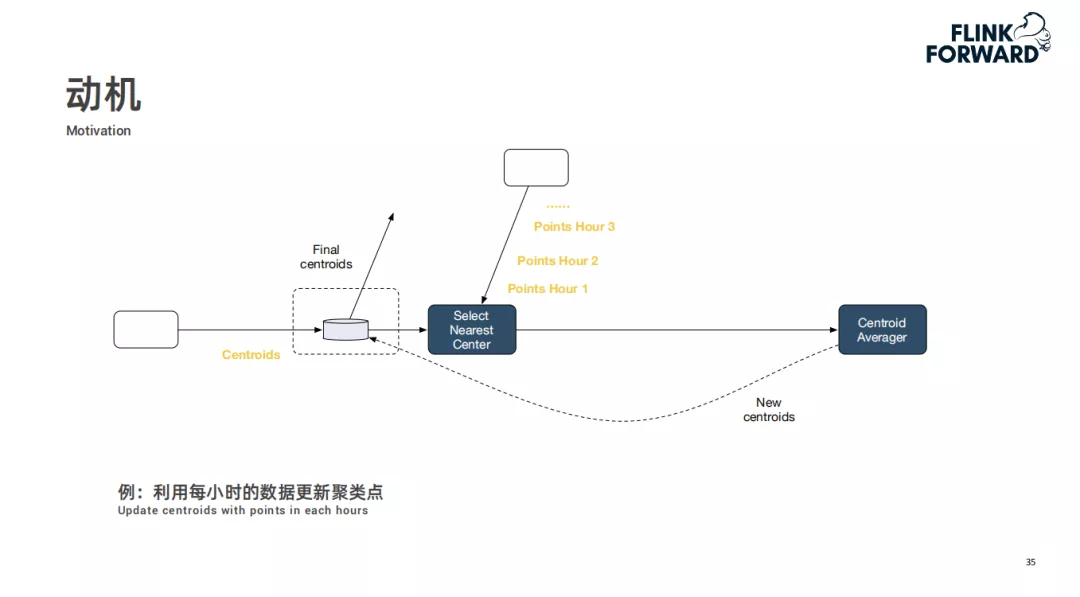
利用每小时的数据更新聚类点。
因此我们需要引入一种新的迭代机制,可以兼容在有限数据上的迭代,并且支持“无限流上每一部分数据分别进行迭代”的语义。
2. Mini-batch 流式 Iteration
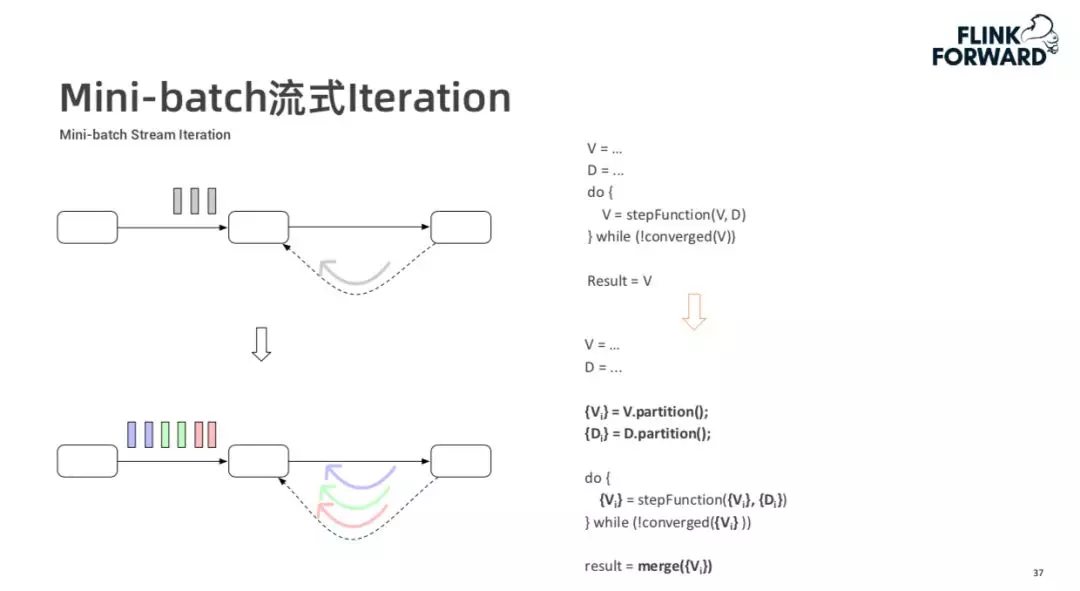
上图是 Mini-batch 流式 Iteration 示例,对于静态数据集,其可以视为只有一个 Mini-batch。对于流式数据,可以将其拆成多个 Mini-batch,他们之间可以独立并行迭代。算子可以自动将单个 Mini-batch 操作扩展到每一个 Mini-batch 上。
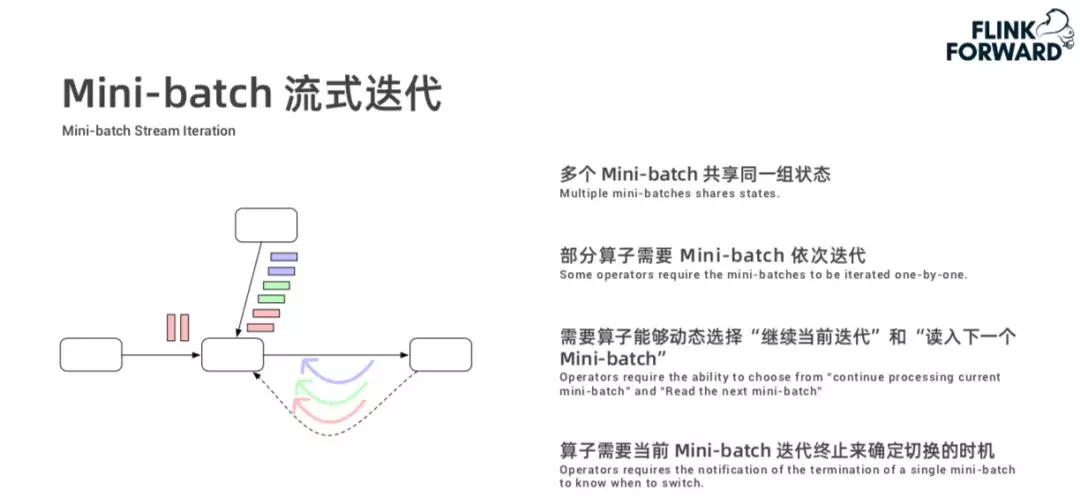
还有一种情况是使用无限的数据集训练一个统一的模型,这种情况下不同的 Mini-batch 共享同一组状态(待更新的模型),其执行机制如上图所示。
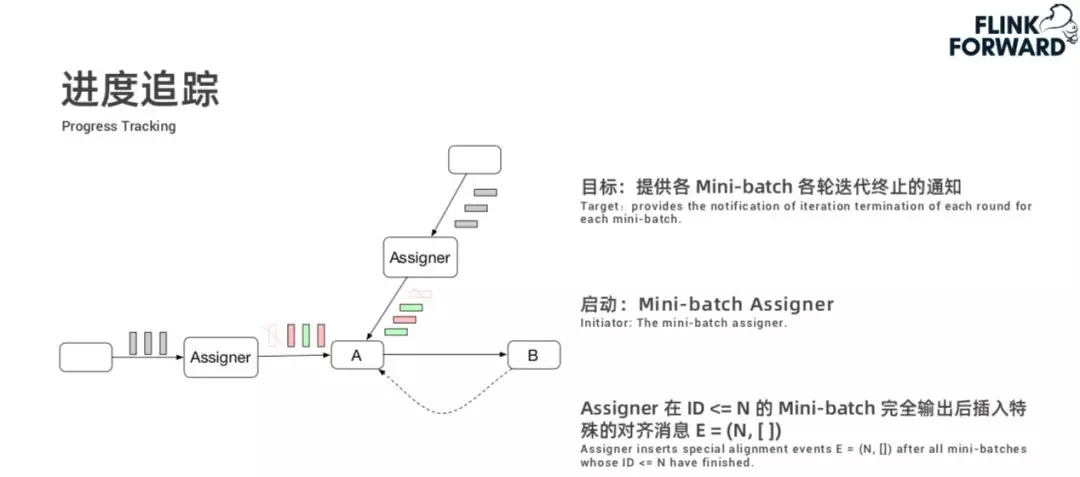
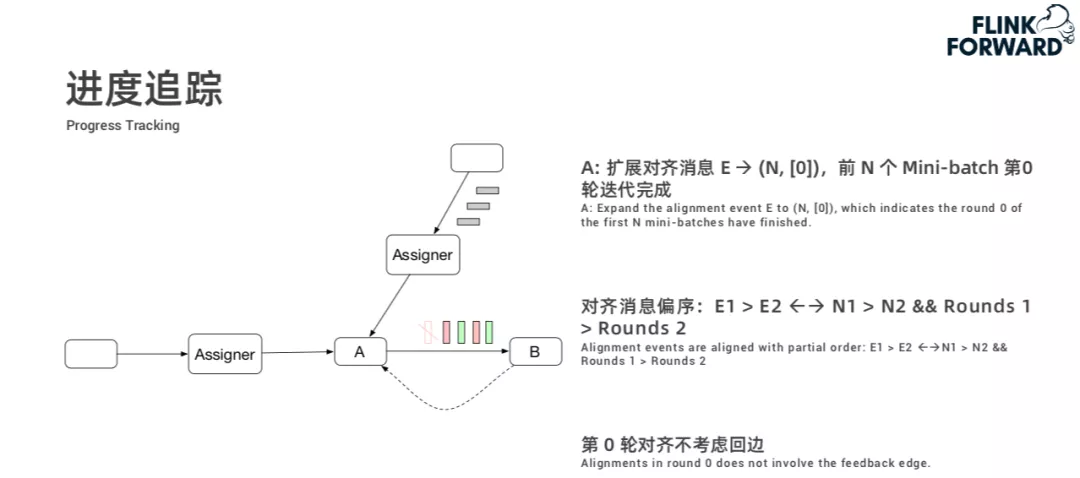
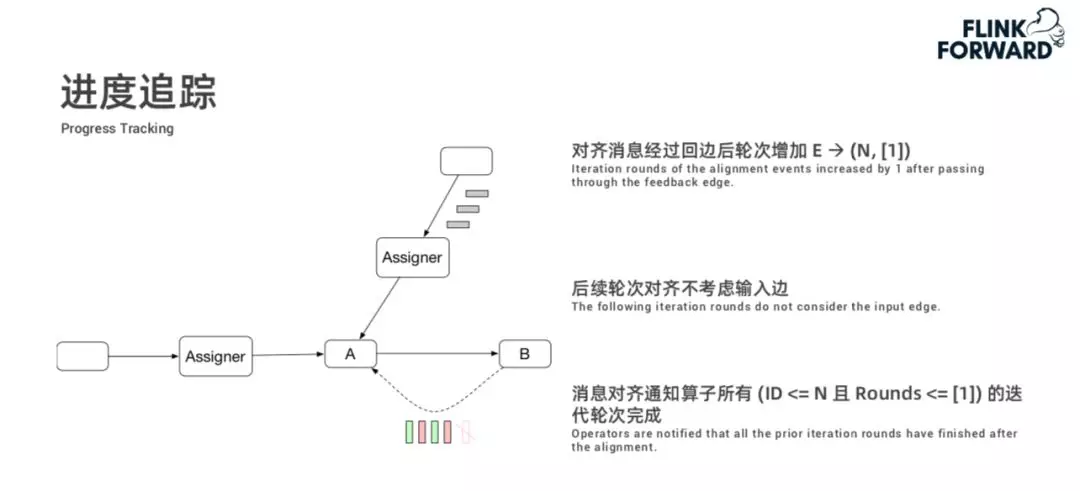
在上述迭代过程中,算子需要知道每个 Mini-batch 的迭代终止情况,我们称之为进度追踪,其目标是提供各 Mini-batch 各轮迭代终止的通知。这种能力通过 Assigner 节点在数据流中插入特殊的标记消息,然后其它算子对标记消息进行对齐来实现。关于进度追踪详细描述,如下:
3. Mini-batch 迭代 API
通过上面的描述可以列出 Mini-batch 迭代 API 的基本框架:

4. 总结

总结来说,我们设计了一种新的基于 Mini-batch 的流式迭代机制,这种迭代机制既可以兼容原来的 DataSet 上基于有限数据上的迭代,也可以支持对无限流上每一部分数据分别进行迭代。未来可以更好地支持在线的机器学习训练和在线的图处理的场景。
今天的分享就到这里,谢谢大家。