Walrus
Introduction
walrus 是一个轻量级olap查询框架。它支持多源异构数据源(hdfs,mysql,clickhouse,kylin,druid...),采用apache spark作为聚合计算引擎,在雪花模型上通过json提供ETL建模和ad hoc数据查询服务。
Background
数据分析、ETL开发人员的日常工作可能有60%-80%(猜的)的时间在整合不同的数据源生成特定的数据报表,简单来说可能就是在写这样一条sql:
SELECT
col_1,col_x..,
AGGREGATE_FUNC(metric_1)..
FROM hdfs_table_1 a
JOIN mysql_table_1 b ON a.xxx=b.xxx
JOIN hdfs_table_2 c ON b.xxx=c.xxx
GROUP BY col_1...
UNION
SELECT
col_2,col_y..,
AGGREGATE_FUNC(metric_2)..
FROM hdfs_table_3 a1
JOIN hdfs_table_4 b1 ON a1.xxx=b1.xxx
GROUP BY col_2...
UNION
...walrus的目标就是将这些重复工作配置化,最大限度的减少代码开发。
Architecture
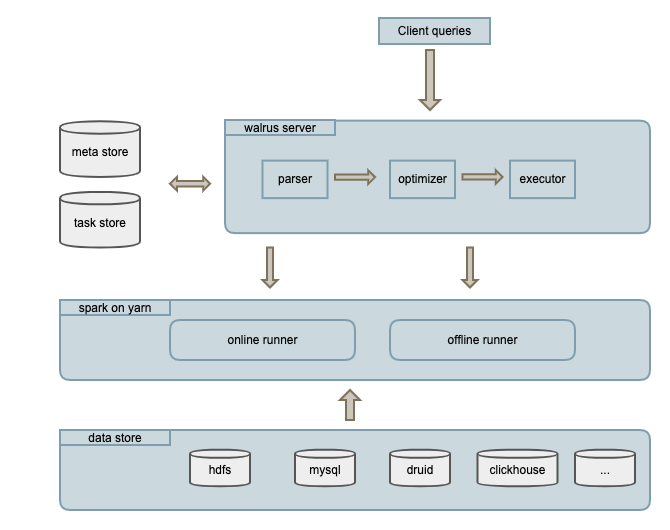
walrus包含walrus_server、online_runner、offline_runner三个进程:
- walrus_server: spring boot web程序,处理用户元数据管理、任务查询等请求。
- online_runner: spark常驻进程。按需预先申请资源并缓存数据,实时监听、处理walrus_server的online task请求。当查询满足online数据时,任务会优先提交到online_runner。
- offline_runner: spark离线任务,由walrus_server通过本地(spark-submit)或者thrift api提交。
Features
- code-less: 配置化etl、ad hoc query,可以减少开发、分析等人员80%(拍脑袋得出的数字)左右的工作量。
- Heterogeneous data source integration: 异构数据源联合查询,高效整合各个数据源。
- High maintainability metadata management: 高可维护性元数据管理,数据口径、计算逻辑统一管理。
- High scalability: 所有节点无状态,支持水平扩展。
- High performance: 通过预缓存数据、合理切割任务、自定义查询计划重写(查询分支合并、数据倾斜优化...)等提供高性能查询服务。
Design
Execution
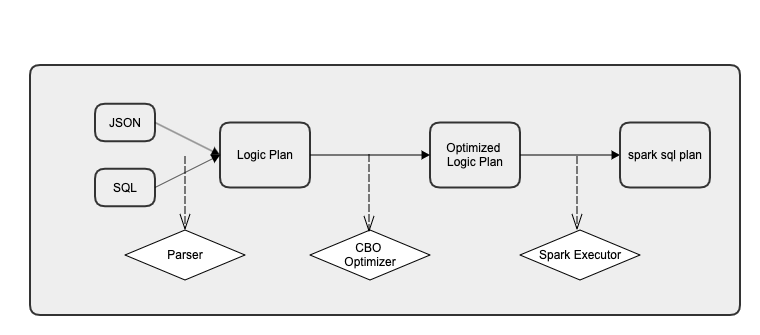
walrus的执行过程:先解析查询成查询计划,对查询计划进行优化重写,最后翻译成spark sql树并提交到spark执行。
-
解析器(parser): 根据meta把query解析成查询计划。你也可以定制自己的parser。
-
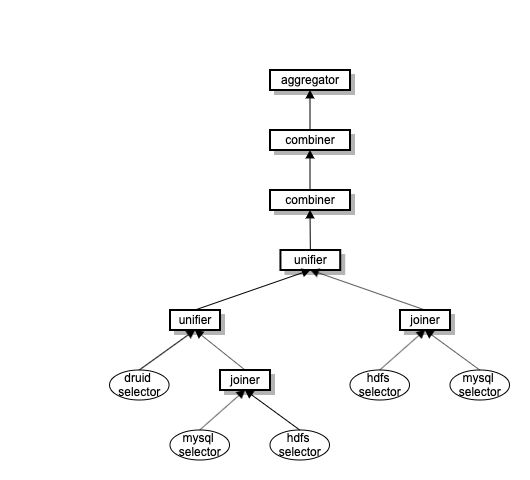
查询计划(Logic Plan): 一棵join+union的嵌套树:
-
优化器(optimizer): 对查询计划树进行重写,默认的有分区合并优化器、数据join倾斜优化器。您可以根据自身的业务数据特点添加自己的optimizer。
Metadata
简单来说,Walrus metadata是对雪花模型的抽象。具体定义可参考pb文件。
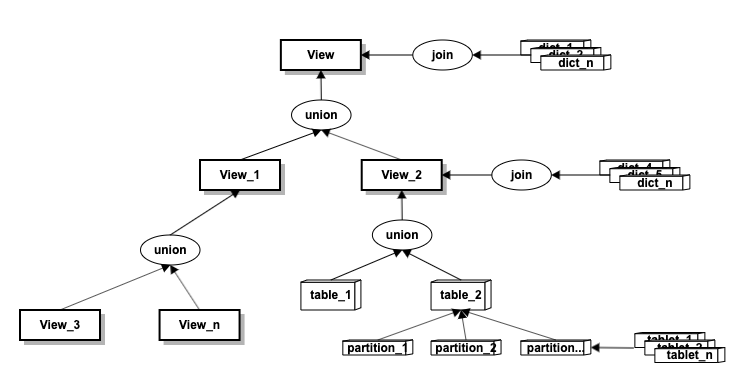
- 视图(view): 一棵join+union的嵌套树,可以做到对事实表和维度表的多层次自由组合。
-
事实表(table)、维度表(dict): 业务事实表和关联维度表。
-
分区(partition):事实表,维度表根据时间跨度和数据量按全量(A)、年(Y)、月(M)、天(D)、小时(H)分区。分区方式决定了任务的拆分粒度和并行度,所以合理选择分区方式可以提高计算效率。
- 维度指标等信息各个分区单独存储,能减少历史重跑、业务变更等运维压力。
- 每个分区数据分版本(tablet)保存,读写分离。
-
维度(dimension)、指标(metric): 除了常规的名称、类型等信息外,维度、指标还可以指定计算逻辑(derivedMode:select[直接select], derived[派生], virtual[虚拟字段],join[关联])。指标目前支持的聚合函数有SUM,MIN,MAX,COUNT,COUNT_DISTINCT,COUNT,COLLECT_LIST等,你也可以在aggregation包下实现你自己的聚合函数。
联系我们
非常欢迎参与到walrus项目中来: https://github.com/WalrusOlap/walrus